|
יחידה 9: רגרסיה וניבוי לינארי >> 9.3: הנחות מודל הרגרסיה |
|||||
הנחות מודל הרגרסיה – לצורך ניבוי y לפי x |
|||||
|
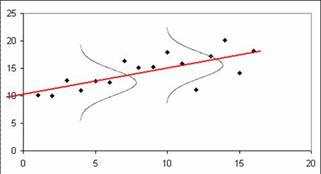
1. הקשר בין המשתנים לינארי.
2. Y מתפלג נורמלית (x לא חייב להתפלג נורמלית).
3. עבור כל הטעויות מתפלגות נורמלית באוכלוסייה (אם היינו לוקחים מדגם מאוד גדול עם נקודות סביב הקו – רוב הנקודות מרוכזות במרכזו וככל שמתרחקים מהקו יש פחות נקודות – עבור כל הטעויות מתפלגות נורמלית סביב y' וסכום הטעויות הוא אפס כלומר הנקודות תימצאנה משני צידיו):
4. ממוצע הטעויות שווה 0: . באופן כללי בכל טווח הערכים בקו ובפרט עבור כל מסוים באוכלוסייה, במדגם ספציפי יכול להיות שהרבה נקודות תיפולנה מעל הקו אבל אם נמשיך לדגום שוב ושוב באוכלוסיה הנקודות תיפולנה משני צידי הקו.
5. אין קשר בין ערכו של x לבין הטעות ב-y: הומוסקדסטיות (homoscedasticity), . דרישה זו משמעה שהמתאם בין הטעות לבין הערך המנובא (y') הוא אפס: , וזאת משום ש-y’ הוא טרנספורמציה לינארית של x . כלומר שאין קשר בין העובדה ש-x הוא קטן או גדול לבין הטעות שנעשה בניבוי y, או במילים אחרות שאין קשר בין y' לבין הטעות סביב הקו. |
|||||
|
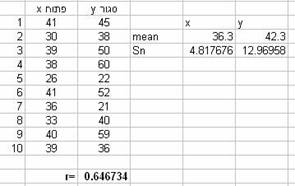
דוגמא: להלן ציוניהם, הן בחלק הפתוח והן בחלק הסגור, במבחן בסטטיסטיקה של 10 תלמידים אשר נדגמו מקרית:
מהו הערך המנובא עבור הסטודנט אשר קיבל ? |
|||||
|
|
|||||
|
פתרון:
תחילה יש לחשב את המתאם בין שני המשתנים: =PERASON(X,Y) עכשיו נחשב את שיפוע הקו ואת נקודת החיתוך עם ציר ה-y ע"י הצבת הנתונים בנוסחאות המתאימות:
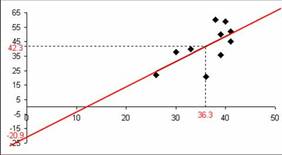
נצייר קו ע"י נקודת החיתוך עם ציר ה-y ומפגש הממוצעים:
הערך המנובא המתקבל: - ערך ה-y של הוא בפועל - הטעות בניבוי היא:
במקרה ספציפי זה קיבלנו אומדן חסר. ברור שמטרת הרגרסיה היא לשם יישום הקו עבור תלמידים אחרים. לדוגמא, אם חלק מהמבחנים אבדו אך נשארו הטפסים של החלק הפתוח. עם זאת, אנו יכולים ללמוד על גודל הטעויות בניבוי על סמך המדגם עליו נבנה הקו. |
|||||
|