Talk:Symbolic Logic:Learning:Inductive Inference
Contents |
[edit] Moved Page to General Area
I have moved to this page to the general area. I appreciate any review and comments.
I dont believe I am saying anything new but I havent seen this exact argument anywhere else.
[edit] Problems with the article
There is doubt in my mind about the validity of prior probabilities. The probability of a model being proportional
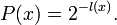
seems OK as a prior but I am not sure if it represents a genuine probability. It is confusing.
There is doubt in my mind about the unbiased nature of the universe generator.
The section "Where there is Less data the Probability Distribution should spread out" needs further work.
It seems in practice it is practical impossible to find genuine probabilities of events in reality.
[edit] First remarks
About the problems mentioned above I should think more, but for now, first remarks.
Section "Probabilities based on Message Length": "Where l(x) is the length of x" – really, the length of x? Or rather, the length of the shortest description of x? --Boris Tsirelson 04:09, 4 March 2011 (EST)
- I made a mistake. I am assuming optimal encoding of the the message X according to its underlying probability distribution. Thepigdog 06:01, 6 March 2011 (EST)
That is, not l(x) but rather l(M)+l(C), right? Or not? What is x, how is it related to C=e(D,M) ? --Boris Tsirelson 04:32, 4 March 2011 (EST)
- x may or may not consist of model M + code C. I am using x as the general symbol for a message.Thepigdog 23:33, 5 March 2011 (EST)
- Where there is a probability function M (the model) that gives probabilities for data then for a particular data sequence D can be encoded using an optimal encoding function e (e.g. arithmetic encoding) to give a code C. Then by transmitting the model M and the code C we can reconstruct the data D. Thepigdog 23:33, 5 March 2011 (EST)
Section "Where there is Less data the Probability Distribution should spread out": "But traditional regression theory does not tell us that" – not quite so; the theory gives us also a confidence region (hyperbolic, for linear regression); this region is narrow near the data and wide far from the data. --Boris Tsirelson 04:52, 4 March 2011 (EST)
- I need to complete this section. I was thinking that a linear regression of y = a + b*x gives estimates for a and b + variances for a and b.
- However y = a + b*x is only one of the models that should be considered. All models need to provide high probabilities for the observed data points.
- The combination of all the models should give a narrow distribution near the observed data points and a spread out further away. Thepigdog 00:21, 6 March 2011 (EST)
- Suppose you have two clusters of data close to two values of x. In the middle there may be a large gap with little data. There should be less narrowing in the gap between the two clusters. From what I understand linear regression doesnt give this.
- I am not saying that the theory of linear regression is wrong. But a linear regression is only one possible model. In theory all possible models should be considered, weighted appropriately, which I believe would give smaller variances near data points and larger variances further away. Thepigdog 00:21, 6 March 2011 (EST)
[edit] A prior or a genuine probability
"There is doubt in my mind about the validity of prior probabilities. The probability of a model being proportional P(x) = 2 − l(x) seems OK as a prior but I am not sure if it represents a genuine probability. It is confusing." – I think, it cannot be a genuine probability simply because it is an improper prior, that is, the sum of these numbers is infinite. Indeed, the sum over all messages of length n is equal to 1; now sum over all n and get infinity. --Boris Tsirelson 12:51, 13 March 2011 (EDT)
- Ahhh thanks for that. I didnt say that the messages must be prefix codes. In fact the models must be described as prefix codes because otherwise we wouldnt know where they end. I will update the article. Thepigdog 08:15, 23 March 2011 (EDT)
"Perhaps it is not correct to think of probability as an absolute and immutable value. Probabilities are determined by: the language used for encoding models (the a-priori knowledge); the data history; computational limitations. Probability is relative by these factors." – Well, if we revise the notion of probability this way, then the meaning of the question "a prior or a genuine probability" is also revised. It cannot be a "genuine probability" in the standard (frequentist) sense. The new sense is for now rather unclear. It can be understood as Bayesian prior. Indeed, it is well known that the choice of the prior becomes less important when the number of available data increases. In fact, this is a reason why improper priors may be used: just because it is not so important what the prior is. This is usually related to big samples, but the same holds for a single "large" observation (the long "message"). Similarly, the choice of the description language should be not so important if the amount of available data is much higher than the complexity of the used language (described in an alternative language). --Boris Tsirelson 13:07, 13 March 2011 (EDT)
- Yes that argument is probably correct as far as it goes. We would need to demonstrate convergence of the probability based on any language in the limit as l(D) -> infinity. But this cant be used as in the freqentist argument to give a definition of probability.
- The question is, "is probability given a limited amount of data a well defined concept". What is the probability given a limited amount of data? At the moment this depends on the language used to encode the model. So the probability given for a limited amount of data depends on the language and seems not to be an absolute probability.
- However the language used to described the language could be regarded as the result of previous experience. The language must have arisen from somewhere. There must always be some previous experience to use as a prior. In effect we are saying that the calculation of probabilities requires us to use a language that has evolved to say things that occur more often with shorter messages. There is an infinite regress there.
- If we hypothesize that there is alternate method of determining the absolute probability then we could imply the argument in reverse to imply that there is one correct modeling language to use for the prior. I think this shows that there can be no way of giving an absolute priority independently of the priors because this would determine the priors, and the priors are the result of previous experience.
- The choice of priors gets even more confusing when dealing with continuous distribution. Thepigdog 08:15, 23 March 2011 (EDT)
[edit] Thoughts
Strictly speaking the length of the representation of the model only gives the probability of the model if the language used to describe the model has been designed so as to be optimal. In other words if the language has been designed to encode the sentences according to their probabilities.
Using mathematics, compressed to give an efficient encoding is an approximation to that. And no better approach seems available.
It would be nice to have a probability that did not depend on prior probabilities. But there is no apparent way to achieve this. You might want to use a weighted sum over all priors, but then how to choose the weights. Back to square one.
For the moment I would say an inductive probability is a function of,
- The event
- The history
- The language used to encode the models / the prior probabilities.
We can think of situations where no possible prior makes any sense (a brand new universe). The dependence on priors is unsatisfactory. :(
- More thoughts (neither original nor well-established).
- We can measure the temperature of a coin at a given second. However, we cannot measure the parameter called "the probability of heads" of this coin at a given second. In this sense, probability is unobservable.
- There is another property, with no well-established name, definition and meaning, but still important. Let me call it "believability" (or maybe "rough probability"). It takes on the values "milli", "micro", "nano", "pico" etc., roughly corresponding to probabilities
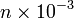 ,
, 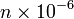 ,
, 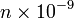 ,
, 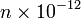 ,... Quite fuzzy, but very important, since it is the ONLY narrow interface between probability theory and reality (experiment, observation).
,... Quite fuzzy, but very important, since it is the ONLY narrow interface between probability theory and reality (experiment, observation).
- Assuming that the parameter of the coin is (approximately) constant (in time), namely 0.5, and tosses are (approximately) independent, the probability theory claims that the event "more than 550 heads in 1000 tosses of the coin" is of "micro" believability. THIS claim can be compared with reality.
- In a more general situation, not assuming constant parameter and independence, we are forced to use only "believability" (rather than probability). Accordingly, exact calculations make no sense. Thus, I hope, the choice of the language (discussed above) is not so important. "Priors" are not "probabilities" but only "rough probabilities".
- A source (not very apt): Emile BOREL, "Probability and certainty", New York 1963 (translated from the French).
- --Boris Tsirelson 04:53, 30 March 2011 (EDT)
- Yes I agree with what you say in practical terms. In practice probabilities are quite vague in many situations. Thepigdog 04:08, 3 April 2011 (EDT)