|
יחידה 3: מבחנים א-פרמטריים >> 3.2: מבחן Wilcoxon למדגמים מזווגים |
|||||||
|
matched-pairs signed rank test The Wilcoxon
זהו מבחן המקביל למבחן t למדגמים תלויים. |
|||||||
|
שלבי עבודה: 1. כמו במבחן t למדגמים תלויים, עבור כל נבדק/זוג מחשבים את ההפרש בין שתי התצפיות . שימו לב: נבדקים בעלי d=0 נזרקים מהניתוח, ומתקנים את גודל ה-n בהתאם למספר הזוגות להם קיים הפרש בין שתי התצפיות התלויות. 2. מדרגים את הערכים המוחלטים (טיפול ב-ties כפי שלמדנו – ממוצע הדירוגים לכולם) 3. סוכמים בנפרד את הדירוגים שמקורם בהפרש (d) חיובי ואת אלו שמקורם בהפרש שלילי. 4. בוחרים את הקטן שמבין שני הסכומים ומגדירים אותו כ-T - זהו הסטטיסטי של מבחן זה. 5. בודקים אם הסטטיסטי T קטן או שווה לערך הקריטי המופיע בטבלה המתאימה עבור נתונה (חד או דו-צדדית). ואז ניתן לדחות את .
שימו לב שבניגוד לטבלאות אחרות בהן השתמשנו עד כה, כאן אנו דוחים כאשר ערך הסטטיסטי קטן או שווה לערך הקריטי המופיע בטבלה. להורדת טבלת Wilcoxon למדגמים תלויים לחץ כאן. |
|||||||
|
התיאוריה שמאחורי המבחן
ההשערות במבחן Wilcoxon לשני מדגמים תלויים הן כי החציונים של שתי האוכלוסיות מהן נדגמו שני המדגמים זהים: |
|||||||
|
Frank Wilcoxon (1882 -1965) |
הרעיון העומד מאחורי השערה זו הוא כי אם באמת אין הבדל בין שני המצבים: לפני ואחרי, אז נצפה שפחות או יותר מחצית מה-d (ההפרשים בין המדידות) ינבעו מהפרש שלילי ומחצית מה-d ינבעו מהפרש חיובי וזאת משום שההבדל בין לפני/אחרי נובע מטעות מקרית. באותו אופן אנו נצפה שאם אין הבדל בין שתי הקבוצות אז הדירוגים הגבוהים והנמוכים יתחלקו באופן שווה בין שתי הקבוצות ולכן ה-T של הדירוגים החיוביים (T+) יהיה דומה ל-T של הדירוגים השליליים (T-). במילים אחרות אנו מצפים ש-(T+) ו-(T-) יהיו דומים. ככל שהפער בין (T+) ו-(T-) גדל אנו מתחילים להאמין שיש הבדל ("משהו") לטובת אחד המצבים לפני/אחרי. |
||||||
|
השערת האפס במבחן Wilcoxon למדגמים תלויים היא שהחציונים זהים: כלומר שהנבדקים לקוחים מאוכלוסיות בעלות חציון זהה, החציון של "לפני הטיפול" זהה לחציון של "אחרי הטיפול". אם החציונים שווים אז הסיכוי שמישהו במדגם/מצב x יהיה גדול ממישהו ב-y זהה לסיכוי שמישהו ב-y יהיה גבוה ממישהו ב-x. כפי שנאמר בפתיחת השיעור, אנו עובדים עם חציונים משום שאנו מדרגים את הערכים בלבד (ולכן דורשים שהערכים יהיו מסולם סדר לפחות), ולכן שואלים רק מה הסיכוי שמישהו בקבוצה x יהיה גדול ממישהו בקבוצה y – מרגע שדירגנו את הערכים אנו כבר לא שואלים בכמה יהיו גדולים או קטנים מהערכים בקבוצה השנייה. הערה: אנו בודקים אך ורק אם סכום הדירוגים המוחלטים הקטן יותר מבין השניים שווה או נמוך לערך הקריטי שבטבלה. חשוב לדעת שקיימת גם טבלה של הערך הקריטי העליון שהינה סימטרית לחלוטין לטבלה של הערך הקריטי התחתון. מטעמי חסכון בטבלאות אנו עובדים רק עם טבלת הערך הקריטי התחתון. |
|||||||
|
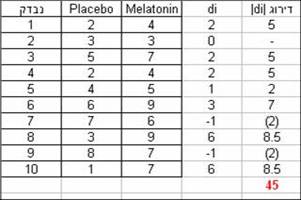
דוגמא: על מנת לבדוק את ההשפעה של ההורמון מלטונין כטיפול בנדודי שינה, חוקר גייס 10 נבדקים. כל נבדק ישן 2 לילות במעבדה. באחד הלילות קיבל placebo ובלילה השני melatonin (double-blind – לצורך השאלה חשוב להבין שלא היה סדר קבוע של לקיחת התרופות). לאחר כל לילה התבקשו הנבדקים לסמן בסקלה שבין 1 ל-10 את איכות השינה שלהם. מה תהיה מסקנת החוקר ברמת בטחון של 95% לגבי יעילותו של מלטונין כטיפול לבעיית שינה? |
|||||||
|
|
|||||||
|
פתרון:
1. הנחות: דגימה מקרית, הזוגות נדגמו מקרית באופן בלתי תלוי האחד בשני
2. השערה:
3. רמת מובהקות: ההשערה חד-צדדית כי מצפים מראש לשיפור באיכות השינה.
4. בדיקת ההשערה: |
|||||||
|
|
|
||||||
|
|
|||||||
|
המספרים בסוגריים מסמנים דירוגי הפרשים שמקורם בהפרש שלילי. |
|||||||
|
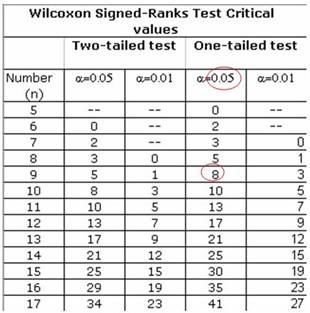
מטבלת Wilcoxon (לטבלה המלאה לחצו כאן):
|
|||||||
|
חד צדדי
|
|||||||
|
5. מסקנה: ערך ה-T שקיבלנו במדגם (4) קטן מהערך הקריטי, לכן נוכל לדחות את ולומר ברמת בטחון של 95% שאיכות השינה גבוהה יותר תחת melatonin. |
|||||||
|
|||||||