|
יחידה 11: בדיקת השערות >> 11.1: הנחות והשערות |
|||||
|
בדיקת השערות (Statistical Hypothesis Testing)
בעולם המדע נשאל שאלות כמו: · האם כדאי להמליץ על טיפול מסוים? · האם הקורס לשיפור הזיכרון באמת עוזר? · האם קבוצת אנשים מובחנת מהכלל? |
|||||
|
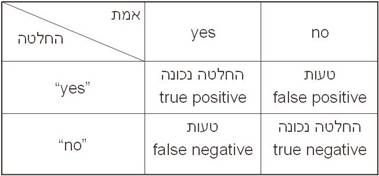
קבלת החלטות
במסגרת האפשרויות העומדות בפני חוקרים, או בעצם בפנינו כיצורים מקבלי החלטות, ישנם ארבעה מצבים הקיימים בעולם:
עתה ננסח את השאלה באופן סטטיסטי: קיימת אוכלוסייה בעלת פרמטרים ידועים. בהינתן מדגם כלשהוא (אשר עבר מניפולציה, לדוגמא קורס בסטטיסטיקה), נשאל האם סביר שהמדגם שייך לאוכלוסייה (הרגילה) או שמא שייך לאוכלוסייה אחרת (שיודעת סטטיסטיקה). |
|||||
|
פילוסופיה
השיטה שבה אנו מבצעים בדיקת השערות הוצעה ע"י פישר, סטטיסטיקאי אנגלי, בסביבות 1920. לפי השיטה, על החוקר לדגום מדגם ולבצע עליו מניפולציה כלשהי. נקודת המוצא של השיטה היא שקיימת אוכלוסיה "רגילה" בעלת פרמטרים מסוימים שמתוכה נלקח המדגם. זוהי השערת האפס. הרעיון שעומד מאחורי השיטה מניח את נכונות השערת האפס ובודק מה הסיכוי לקבלת ממוצע מדגם כפי שקיבלנו באופן מקרי תחת הנחת נכונות השערת האפס. אם ממוצע המדגם שלנו קיצוני מספיק – נמצא לפחות בין-5% המקרים הקיצוניים ביותר בהתפלגות, למשל, אזי נוכל לטעון שככל הנראה מדובר במדגם הלקוח מאוכלוסיה אחרת.
לצורך הבנה ברורה יותר של התהליך, אנו נחלקו באופן טכני ל-5 שלבים: 1. הנחות 2. השערות 3. רמת מובהקות 4. בדיקה ההשערה בפועל 5. מסקנה
בשלב ההסבר הכללי נתחיל עם מושג ההשערות ובהמשך נדבר על ההנחות. מאוחר יותר נניח תחילה את ההנחות. |
|||||
|
לדוגמא: ידוע שממוצע הציון במבחן הפסיכומטרי בכלל האוכלוסייה הוא . קבוצה של 50 אנשים עברה קורס הכנה לפסיכומטרי וממוצע הציונים של קבוצה זו הוא 520. האם הם עדיין נחשבים לשייכים לאוכלוסייה הרגילה, או שבעקבות הקורס ניתן לומר שהם שיכים לאוכלוסייה אחרת (אוכלוסייה בעלת ?
|
|||||
|
השערות
הפילוסופיה שמאחורי בדיקת ההשערות כוללת שתי השערות:
1. השערת אפס (null hypothesis) הטוענת טענה כלשהי אשר בתהליך בדיקת ההשערות ננסה להפריך אותה: המדגם לקוח מאוכלוסייה בעלת
2. השערת אלטרנטיבית (alternative hypothesis) שהיא כל המצבים המשלימים להשערת האפס. אם נדחה את השערת האפס אזי ניוותר עם ההשערה האלטרנטיבית: המדגם אינו לקוח מאוכלוסייה בעלת אלא מאוכלוסייה אחרת
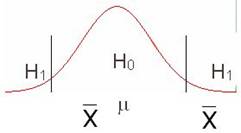
בצורה גראפית ניתן להמחיש זאת כך:
האזור שבמרכז ההתפלגות הוא האזור שאם ממוצע המדגם שלנו יימצא בו לא נוכל לדחות את . האזורים הקיצוניים הם האזורים שאם ממוצע המדגם שלנו יימצא בהם, נחליט הוא שייך ככל הנראה לאוכלוסייה מתוך השערה האלטרנטיבית. זאת כי הסיכוי לקבל מדגם כה קיצוני באופן מקרי הינו נמוך מספיק. |
|||||
|
הנחות (שימו לב שבהמשך ההנחות יקדמו להשערות)
בדיקת ההשערות מתבצעת על התפלגות הדגימה של ממוצעים. מכיוון שאנו רוצים לבדוק האם ממוצע מדגם מסוים שונה מממוצע האוכלוסייה, נוכל לעשות זאת רק על התפלגות הדגימה של הממוצעים (שכזכור היא התפלגות המורכבת מממוצעים). אנו נשווה ממוצע מדגם בגודל מסוים להתפלגות הדגימה של ממוצעי מדגמים באותו גודל. רק כך נוכל לקבל הערכה של עד כמה ממוצע המדגם שלנו אכן שונה מממוצעי מדגם אפשריים אחרים באותו גודל.
בשיעור שעבר למדנו שהתפלגות הדגימה של ממוצעי מדגם הינה בקירוב נורמלית כאשר גודל המדגמים גדול מספיק. בזכות עובדה זו נוכל להעריך את מיקומו היחסי של ממוצע מדגם ביחס להתפלגות הדגימה של הממוצעים. באמצעות נתוני האוכלוסייה וגודל המדגם נוכל לבנות (באופן תיאורטי) את התפלגות הדגימה של הממוצעים.
כך נבדוק האם סביר שהמדגם לקוח מהתפלגות הדגימה של ממוצעים אשר נבנתה על בסיס נתוני האוכלוסייה הידועים, ובאופן עקיף נענה לשאלה האם סביר שהפריטים שמרכיבים את המדגם נלקחו מהאוכלוסייה הנתונה או שמא נלקחו מאוכלוסייה אחרת.
הנחה חשובה נוספת הינה של אי תלות בין המדגמים השונים שנדגמו לצורך בניית התפלגות הדגימה. אי התלות מושגת ע"י דרישה/הנחה של דגימה מקרית. נושא זה ילמד בהרחבה בקורס שיטות מחקר בשנה ב'. |
|||||
|