|
שאלות נפוצות
- רגרסיה וניבוי לינארי |
|
◄
לקורס המקוון |
|
לדף הראשי
► |
|
1. שאלה:
ברגרסיה, האם מכל קו שעובר דרך נקודת מפגש הממוצעים
סכום ריבועי הסטיות הוא מינימלי?
במילים אחרות, אני לא לגמרי מבינה איך יכול להיות שיש מספר קוים שסכום
הסטיות מהם הוא אפס וסכום ריבועי הסטיות הוא מינימלי ורק קו רגרסיה
אחד. |
| |
|
פתרון:
כל קו רגרסיה עובר דרך מפגש
הממוצעים. יש קו רגרסיה אחד בלבד אשר עונה על קריטריון מינימום
הריבועים עבור Y וקו רגרסיה אחד בלבד אשר עונה על קריטריון מינימום
הריבועים עבור X. שני קווים אלו עוברים דרך מפגש הממוצעים. |
|
|
|
2. שאלה:
הייתה את השאלה הבאה:
ג'ייקוב מאמין שניתן לנבא את רמת האינטליגנציה של אנשים ע"פ יחסם
למוזיקה. הוא דגם מקרית 10 אנשים, ולכל אחד מדד את ה-IQ והיחס למוזיקה
(מ-1="שונא" עד 10="לא יכול בלי").
איזה IQ ינבא ג'ייקוב לאדם שיידרג את יחסו למוזיקה כ-"7"?
התשובה הייתה:
ניתן לנבא רק את דירוג ה-IQ ביחס לנבדקים האחרים
למה? אני בטוחה שפספסתי פה משהו בסיסי אבל מה? |
|
|
|
פתרון:
IQ - משתנה בסולם יחס.
יחס למוזיקה - משתנה בסולם סדר.
מאחר ורגרסיה (לפחות זו שלמדנו) מתאימה אך ורק למשתנים מסולם רווח
ומעלה, או במילים אחרות, מבוססת על מתאם פירסון - לא ניתן לבצע רגרסיה
ישירות על הנתונים הללו.
המתאם שמתאים למקרים האלו הוא מתאם ספירמן. כזכור, מתאם ספירמן
מחושב באמצעות דירוג של שני המשתנים ואח"כ
חישוב מתאם על פי הנוסחה הגנרית (שלמדנו בהקשר
של פירסון). כלומר, אנחנו יכולים "להתלבש" על החלק שבו מבצעים את
פירסון (הנוסחה הגנרית למתאם) ולהגיע לנוסחת הניבוי, אבל, מה שזה אומר,
זה שהערכים שנקבל בנוסחת הניבוי יהיו דירוגים של המשתנים
המקוריים ולא המשתנים עצמם (כי את חישובי המתאם ביצענו על הדירוגים)
ולכן לא ניתן לנבא את ה-IQ עצמו אלא רק את הדירוג שלו ביחס לאחרים.
כלומר, נבסס את הניבוי לא על הערכים עצמם, אלא על
דירוגי הערכים (מכיוון שמחושב מתאם ספירמן בלבד). |
|
|
|
3. שאלה:
בקורס הווירטואלי (9.4) נאמר : "מידת הקיצוניות ב-X
(ציון תקן) היא פונקציה של חלק אמיתי ושל חלק מקרי." האם זו טעות
ולמעשה דיברו על Y? כי למדנו ש-Y, הציון האמיתי, הוא זה שמורכב מחלק
מנובא אמיתי וחלק טעותי, ואם הוא קיצוני אז הטעות שיחקה לטובתו.
אח"כ אומרים ש"ממוצע הטעויות שווה ל-0, אנו מצפים (הניבוי הטוב ביותר)
שבתכונה השנייה הטעות תהיה קרובה יותר ל-0". --אבל אמרנו שממוצע
הטעויות שווה ל-0 עבור Y ולא X ! ובכלל, מה הכוונה ב"תכונה השנייה"?
האם הכוונה לנקודת Y אמיתי נוספת לאותו X? |
|
|
|
פתרון:
אם קוראים למשנה X או Y זה באמת לא משנה שום דבר,
כל עוד אנחנו עקביים עם הסימון. לכן כל דבר שנאמר על X נכון גם לגבי Y,
בכיוון ההפוך. זה חייב להיות כך, כי אין הבדל מהותי בין ניבוי X על פי
Y ובין ניבוי Y על פי X. ובכלל זה, אנחנו יכולים לקרוא לגובה X ול-Y
משקל, או הפוך. כמובן שזה לא ישנה שום דבר.
נראה כי הכוונה בשורה המצוטטת היא שככל שהמשתנה המנבא, X, רחוק יותר
מהממוצע, כך נצפה שהמשתנה המנובא, Y, יהיה רחוק יותר מהממוצע- אבל
בפחות מ-X.
יתר על כן, הטעות עבור ניבוי Y המתאים ל-X הרחוק מאוד מהממוצע תהיה
גדולה יותר מהטעות עבור Y של X קרוב לממוצע. |
|
|
|
4. שאלה:
המושג SSREG, לא הצלחתי
למצוא הגדרה שלו. |
|
|
|
פתרון:
SS=סכום הריבועים
REG= רגרסיה ('y)
יש גם TOT שזה של הציונים המקוריים (y)
ו- ERROR שזה כמובן הטעויות.
SSreg הוא סכום הריבועים של כל ערך מנובא (y') מממוצע ערכי ה-y של
המדגם (y גג).
למעשה, המרחק בין ערכי ה-y בפועל לבין ממוצע ערכי ה-y של המדגם מתחלק
לשני קטעים (כפי שמדגים הציור):
1. המרחק בין הערך בפועל לבין y'
2. המרחק בין y' לבין הממוצע
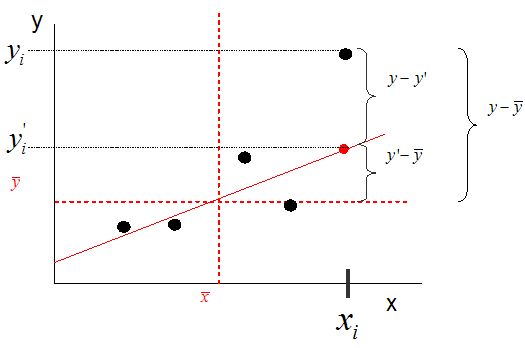
חלק מספר 1 זה הטעות שלנו, חלק שאנו לא יודעים להסביר באמצעות הרגרסיה
(ולכן סכום הריבועים שלו מכונה SSerror).
חלק מספר 2 זה החלק שאנו כן מצליחים להסביר באמצעות הרגרסיה (ולכן סכום
הריבועים שלו מכונה SSreg).
שניהם ביחד נותנים לנו את סכום הריבועים הכללי - SStot. |
|
|
|
5. שאלה:
מבקשים לחשב מתאם בין Y ל-'Y
בתשובות נתונה הנוסחא ryy' = ry.xz .
ושאלתי היא:
א. מה ההיגיון בנוסחא הזו, למה המתאם בין המנובא לנצפה שווה למתאם בין
המנובא למנבאים? (מה שמוביל אותי לשאלה השנייה וההרבה יותר עקרונית)
ב. איך יכולה להיות נוסחא גנרית לחישוב מתאם בין ציונים נצפים לציונים
מנובאים אם אחת ההנחות הבסיסיות של הרגרסיה היא שאין קשר בין הטעות
בניבוי למשתנה המנבא?
הרי כאן, טרנזיטיבית אנחנו מוכיחים קשר (גם אם קטן) בדיוק כזה! הרי 'Y
היא בדיוק Y ועוד הטעות, לכן ע"י טרנספורמציה לינארית המתאם שנמצא יעיד
על קשר בין Y נצפה לבין הטעות. |
|
|
|
פתרון:
א. השוויון נובע מכך שטרנספורמציה ליניארית אינה
משפיעה על המתאם, והרי y' היא טרנספורמציה ליניארית של X ושל Z. הנוסחא
מסורבלת וארוכה אבל אם תסתכלי טוב תראי שיש שם רק מכפלות ליניאריות של
כל המתאמים האלה, והוספת קבועים. אמנם במתאם מרובה זה לא נראה בדיוק
כמו קו- אבל זה מישור (שטוח). תחשבי כמה יותר מסובך הכל היה אם זה לא
היה מישור, אלא הרים וגבעות (כלומר, רגרסיה לא ליניארית מרובה!).
ב. אנחנו הרי לא יודעים מה ה-Y האמיתי. אבל בעצם "הקשר הגנרי" הזה רק
אומר שהיכולת שלנו לנבא את Y היא טובה רק באותה המידה שהנבאים שלנו
באמת מנבאים את Y! אני חושב שזה די אינטואיטיבי
כלומר- ניתן להסיק את "Y האמיתי" ממה שנבאנו רק באותה מידה שניתן להסיק
את מה שחשבנו שיהיה Y האמיתי מהנבאים שלנו- בגלל שזאת אותה הסקה בדיוק,
למעשה. |
|
|
|
6. שאלה:
1. האם לכל ערך Y תהיה טעות אחרת? או ש-Ye זהה בכל
התצפיות?
ואם התשובה היא לא,אז איך אנחנו יכולים ללמוד על גודל הטעות בניבוי על
סמך המדגם שלפיו נבנה הקו? (אם הטעות נשארת זהה אז זה די אקראי,לא באמת
נוכל להחיל את זה על מקרים אחרים..)
2.בקורס הוירטואלי ובתרגול הודגש שלגבי נתונים גולמיים אם r שווה בערכו
המוחלט ל-1, קווי הרגרסיה לא יתלכדו (אלא אם כן סטיות התקן יהיו שוות
בערכן,כמו בציוני תקן) אבל גם במטלה וגם בשאלות לדוגמא (בשאלה עם הטבלה
והנתונים המשתנים) הם הראו שקווי הרגרסיה כן מתלכדים במקרה ש r=1 (למרות
שסטיות התקן לא זהות)
מישהו יכול להסביר את התופעה? |
|
|
|
פתרון:
לגבי השאלה הראשונה:
הטעות שונה בין כל אחת מהתצפיות, אם תסתכלי באחד הגרפים הראשונים בקורס
הוירטאולי על רגרסיה וניבוי ליניארי יש גרף עם נקודות מסביב לקו
הרגרסיה וקוים קטנים שמחברים שמראים את המרחק של הערך האמיתי- שזה הערך
שמצאנו במגדם לערך המנובא- שזה הערך שעל הקו הרגרסיה. הטעות היא המרחק
בין ערך y אמיתי כלשהו (ערך מהמדגם) לערך המנובא (כלומר זה שעל קו
הרגרסיה), הטעויות שונות בגלל של-Y עצמו יש שונות- כלומר הפיזור של
הערכים האמיתיים הוא לא אחיד וקו הרגרסיה בעצם מייצג את הקו שיגרום
למינימום הסטיות (הריבועיות) ממנו.
בעצם כדי לחשב את גודל הטעות צריך לחשב את הפער בין הערך האמיתי (שאותו
קיבלנו במדגם) לבין הערך המנובא (שהוא תוצאה של נוסחת הרגרסיה).
שאלה 2:
יש שני דברים שצריך לשים לב אליהם- אחד זה מהן סטיות התקן ואם הן זהות
ושני זה מהי נוסחת הרגרסיה ואם היא זהה לשני הקווים (כלומר קו שהוא
ניבוי של y באמצעות x, וקו שהוא ניבוי של x באמצעות y). למשל, כשסטיות
התקן והממוצעים שווים, הנוסחאות של שני הקווים תהיינה זהות אבל הקווים
לא בהכרח מתלכדים (בציונים גולמיים), לעומת זאת, כש-r שווה 1, הקווים
מתלכדים אבל הנוסחאות לא בהכרח זהות. בציוני תקן, כאשר r=1 או r=-1
הקווים מתלכדים כי בעצם סטיה אחת ב-x גוררת לאותו שינוי בדיוק ב- y
כלומר, אם למשל x=1.5 (כלומר ציון תקן של סטיית תקן וחצי מהממוצע), אז
y יהיה שווה אותו דבר כי המתאם הוא מושלם- גם y יזוז בדיוק בסטיית תקן
וחצי, וגם אם בקו השני ננסה לנבא את x באמצעות y יתקבל אותו x. אז
במקרה כזה הקווים מתלכדים.
בעצם בשאלה, אם תשימי לב מדובר בנוסחאות שונות. הקווים מתלכדים
והנוסחאות שונות. כלומר, זה בדיוק מה שצריך לבדוק, יכול להיות מצב שבו
הנוסחאות שונות והקווים מתלכדים, ויכול להיות מצב שבו הנוסחאות זהות
והקווים לא מתלכדים. |
|
|
|
7. שאלה:
תשס'ד מועד א', שאלות סגורות- 7:
נתונים שני קווי רגרסיה לניבוי המשתנים: y1, ו-y2 לפי אותו משתנה x.
נתון: rxy1 < rxy2
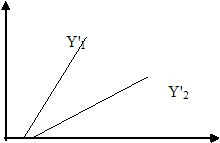
מה נכון לגבי היחס שבין Sny1 ל-Sny2?
א. Sny1=Sny2
ב. Sny2>Sny1
ג. Sny2<Sny1
ד. לא ניתן לדעת.
ה. קיימת טעות בגרף מאחר ושיפוע הקו לניבוי y1 גדול מ-45
מעלות.
התשובה היא ג, אני אשמח להסבר למה זה ככה, על מה מסתמכים- איך בודקים
את זה? |
|
|
|
פתרון:
רואים בציור ששיפוע קו 1'Y גדול יותר משיפוע 2'Y
ונתון rxy1 < rxy2 .
מכאן אפשר להסיק על סטיות התקן : מכיוון שהשיפוע שווה למכפלת היחס בין
סטיות התקן וr,
אם השיפוע של 1'Y גדול יותר ו-r שלו קטן יותר, סימן שסטיית התקן שלו
(Sny1) צריכה להיות גדולה יותר מ- Sny2 (ע"מ שהשיפוע שלו יהיה הגדול
יותר).
נניח לרגע שהמתאם היה שווה. אם באחד מהם הזווית יותר גדולה, זה אומר
בהכרח שס"ת של y שלו יותר גדולה משל הגרף השני (כי לשניהם אותו x).
ועכשיו לא נניח שוויון מתאמים, אם אנחנו עוד יודעים שדווקא המתאם של
הגרף המשופע יותר נמוך מהשני (זה בעל המתאם הגבוה יותר), אז ס"ת של y
שלו צריכה לחפות גם על המתאם הנמוך וגם להוסיף עוד שיפוע. |
|
|