Application

This
is a Win32 application, which enables the user to see the results of
Reinforcement Learning on the problem of agent-navigation.
In
order to understand the changes in learning derived from the learning
context (the world), various worlds can be selected, and the
Reinforcement Learning algorithms can be performed on each of them.
Agent which had been trained to learn a specific policy can be saved to
disk and then placed in other worlds.
User-Interface
The Windows
application enables the user the following things:
·
Choose an agent
·
Choose a world
·
Find the best policy of
the chosen agent in the chosen world by using the Sarsa Algorithm
·
Create a random policy for
this agent
·
Evaluate a policy found
for the agent (or the random policy) by using the TD0 algorithm
·
Show the chosen agent
navigate in the chosen world using its policy
·
Save Agent’s policy to
the disk
The program
provides a graphical user interface to allow the user full control over
the various parameters of the agent (number of eyes, view range, life
span ext), the world (can be chosen from a list of worlds), the
algorithm (number of iterations) and the navigation shown.
Usage
Following is a
diagram describing the application interface:
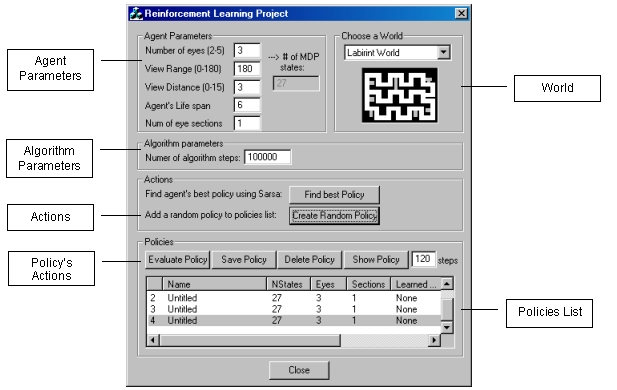
The application UI includes the following controls:
|
Agent’s
Parameters: ·
Number of Eyes –
Determines the number of agent’s eyes. ·
View Range –
Determines the vision field of the agent ·
View Distance –
Determines how “far” the agent sees. Distance in cells. ·
Agent’s life
span – Determines
the life span of the agent in the world (number of steps he
performs in the world before it dies). ·
Number of Eye
sections – number
of vision sections of the agent, meaning number of discrete
areas in which agent can see something, in each eye. · Number of MDP states – is derived from the chosen parameters. The number of MDP states depends on number of agent’s eyes and number of eyes sections.
|
|
World: · Choose a world from the given list. This will be the world in which the agent can find its best policy, calculate it or navigate in it. The agent can be trained in one world and evaluated or viewed in another. The chosen world is the one in which the user action will be performed.
|
|
Algorithm
Parameters: ·
Number of
Algorithm Steps –
Determines the number of iterations the requested algorithms
performs before returning the calculated results. Note: The
number of steps defines the number of updates which will be
performed. Since the application always completes an agent’s
life span, it may perform a couple of extra steps.
|
|
Actions: Each of the following actions creates a new policy, for the chosen agent.
The created policy will be added to the List of Policies with
all its parameters. ·
Find Best
Policy – Pressing
this button initiates the Sarsa algorithm with the chosen agent
in the chosen world, for the number of steps specified, in order
to find the best agent’s policy. Note that a best policy in
one world is not necessarily the best policy in a different
world. ·
Create Random
Policy – creates a
random policy for the specific agent chosen.
|
|
Policies: This
tab includes all the operation which can be done on a given
policy, whether it was found by the Sarsa algorithm or is was
created randomly. The following actions can be performed on a policy: ·
Evaluate Policy
(TD0) – Pressing
this button initiates the TD0 algorithm that evaluates a given
policy. The policy is evaluated on the world which is currently
chosen, for an agent with parameters specified in the policy’s
line in the list. · Save Policy - Save policy to disk. A dialog is opened and lets the user choosing the policy’s file name. All policies are saved under the application’s directly with the extension “.plc”. Each saved policy will be displayed in the list of policies next time application is launched. ·
Delete Policy
– Deletes chosen
policy from disk and from policies list. ·
Show Policy /
Hide Policy – Let
the agent (whose parameters are specified in the policy list)
navigate in the chosen world according to the chosen policy. A
view of the world will be displayed. the agent is situated in a
random position inside the world, and navigates according to the
policy. ·
Number of steps
-
number of navigation steps of the agent in the world used when
choosing the “Show Policy” option.
|
|
List Of Policies: A policy is added to the list each time “Find Best Policy” or
“Create Random Policy” buttons are pressed. The following parameters are presented (and saved if requested) for each policy: ·
Policy Name –
when the policy is created this will be an informative name: ·
Number of states
– is determined by the next 2 parameters ·
Number of eyes ·
Number of sections
(for each eye) ·
Learned On –
specifies the world in which the policy was found. Will be
"None" for a randomly created policy. ·
Score –
policy’s score. This is an average score over all states. ·
Range – view
range of agent (0-180) · Dist – view distance of agent
|
![]()