Results
|
||
|
Getting Started In
order to understand the results properly we’ll first specify the
reward functions that we used. As explained in the “reward’
sub-section of the “Algorithm” section, immediate reward was used in
most cases in which substantial results were obtained. We
began with worlds in which there was no grass, and the only goal was for
the agents to learn to navigate properly in the world (not bumping into
walls). The
immediate reward we used was the highest for moving forward,
intermediate for turning right or left, and the lowest for not moving
(this happens when the agent tries to move forward while facing a wall). We
did not give higher reward for exploring unvisited areas of the world,
thus it is clear that from the given reward function, an iterative route
in which the agent does not bump into walls is enough to yields high
scores. A Complex World At
first we were not able to obtain good results, the agents, even after
many Sarsa iterations, did not learn the most basic principal of a
proper navigation – avoiding bumping into walls. Our assumption was
that the world we used was too complicated– it contained many turns
and curves and thus the agent encountered many different states during
his navigation (some of them very rarely). This made the learning
process tedious and long. In addition, we gave the agents many eyes and
many eyes sections, which also increased the number of MDP states. A Simple World Thus the first step
was to let the agent learn in a simpler world, in which the number of
states which it encounters is smaller. In addition we used an agent with
only 3 eyes, and one or two eyes sections.
In this
world, the agent learned to navigate quite quickly. The best agent did
not bump into walls at all, and moved forward whenever it was possible. Labyrinth World Now we moved to a
more challenging world, the labyrinth world. An interesting
experiment we conducted was to place this agent (which was trained
within the Labyrinth world), in the simple world and observe the way it
will navigate there. We have found that it displayed the same behavior
and skills as the agent which was trained originally in the simple
world. The Labyrinth
world, being more complicated than the simple world, includes more MDP
states, but since we used the same reward function, the resulted policy
was the same for the states that were encountered by the agent in both
worlds. Adding Grass – The good life The next step was
to add Grass lawns to our worlds. The grass areas were expected to be a
preferred location for the agent to be in, since the agent gets a higher
reward function when standing on grass. The agent was modified to be
able to spot grass when viewed in one of his eye sections. The agent was
expected to navigate in the direction of the grass once he views grass,
and stay in grassy lawns after entering them. Again, when the grass is
out of agent’s sight, he will not go to its direction, since he does
not have any other sensor, which can direct him to the grass. Thus if
there is a wall between the agent and the grass, the agent will not
“see” the grass (his eyes will bump into the wall first), and as a
result will not navigate to its direction. We added
grassy areas to the Labyrinth world. The areas were added in specific
locations, which forced the agent to turn right or left in order to
enter the grass area. This way, the agent could not enter a grassy area
just by moving forward, but rather had to actively prefer turning
towards the grass (when viewed by one of its eyes). Additionally, all grassy areas in the Labyrinth world were
surrounded by walls.
The best
agent learned to navigate properly, as it did in the Labyrinth world
without the grass, but in addition, once the agent viewed a grass area,
it turned in its direction, entered the grassy area, and continued
navigating inside the grassy area. Policy Verification – The Grass Lawn World In the labyrinth
world all grassy areas were surrounded by walls, thus this world did not
really verify what would the agent do when located inside a grassy area,
not surrounded by walls. Will he exit the area and keep on navigating
till he finds another grass? Or will he stay in the grass lawn? In order
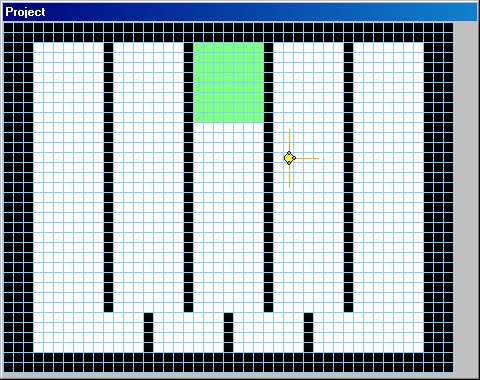
to test this we created another world: the “Grass Lawn”. This world
has no walls, but it has a large grass lawn in the middle of it. It was
used to check whether the agent prefers grass over non-grass under no
other navigation constrains.
As one can see from
the navigation route below, the agent which was trained in the grassy
Labyrinth world preferred grass over non-grass, and once the agent
entered the grass area, it stayed there and navigated within the grass
area. “What’s Behind Door 3” World An exciting
experiment was to see whether we can use our agent for a “practical”
assignment – a grass finder. We created a very specific world for this
assignment in which the agent can explore five different aisles where
only one of these aisles ends up with a grassy area. The agent can see
the grass only if he is entering inside the aisle, thus cannot know in
advance whether he should enter a specific aisle and he should explore
them all in order to find the grassy heaven. Once it does enter the
right aisle and finds the grass, he should stay there. The algorithm
yielded an agent that had these exact properties. They kept on
navigating inside the different aisle, but once entered the grassy
aisle, they stayed inside it (and call their masters if they could).
A Moral Dilemma: To turn or not to turn? Since the agent
trained in “What’s behind Door 3” world always sees the grass from
the same position (moving forward, the grass is right ahead of it) it
learned how to act in this specific situation, but did not learn how to
act in situations which it did not encounter. When training the 3
eyes agent, the agent always sees the grass with the middle eye – the
one looking forward. When we put this
agent in the Labyrinth World, it did not behave properly. In the
Labyrinth world, a 3-eyes agent can view the grass only with its left or
right eye, while viewing a wall or nothing in the middle eye. (This was
done intentionally as to make the agent turn into the grass area and not
just continue walking straight ahead towards it). The resulting agent
behavior is as follows: as long as it does not see grass, it navigates
properly without bumping into walls and without stopping. Once the agent
sees the grass in his left or right eye, it turns towards the grass and
then away from it (to its original direction), and then towards the
grass again indefinitely. It looks as if the agent does not know which
option to choose – turn towards the grass, or keep navigating forward
(this is of course an anthropomorphism of the agent, but at this stage
we do believe it has a rather humanoid personality). This policy results
in endless turns in which agent does not move forward at all.
|
||
|
|