If you need help with using
the .mp3-files, click here:
Onomatopoeia: Cuckoo-Language and Tick-Tocking
Back to home page
Back to "Occasional Papers"
If you need help with using
the .mp3-files, click here:
![]()
Onomatopoeia: Cuckoo-Language and Tick-Tocking
The Constraints of Semiotic Systems
This paper is a brief phonetic investigation of the
nature of onomatopoeia. Onomatopoeia is the imitation
of natural noises by speech sounds. To understand this
phenomenon, we must realize that there is a problem
here which is by no means trivial. There is an infinite
number of noises in nature, but only twenty-something
letters in an alphabet that convey in any language
a closed system of about fifty (up to a maximum of
100) speech sounds. I have devoted a book length study
to the expressiveness of language (What Makes Sound
Patterns Expressive? -- The Poetic Mode of Speech Perception),
but have only fleetingly touched upon onomatopoeia.
In this paper I will recapitulate from that book the
issue of acoustic coding, and then will toy around
with two specific cases: why does the cuckoo say "kuku"
in some languages, and why the clock prefers to
say "tick-tock" rather than, say, tip-top.
Only fleetingly I will touch upon the question why
the speech sounds [s] and [S] (S represents the initial consonant of shoe; s the initial consonant of sue)
serve generally as onomatopoeia
for noise (in my book I have explored the expressiveness
of these sounds at much greater length). By way of
doing all this, I will discuss a higher-order issue
as well: How are effects translated from reality to
some semiotic system, or from one semiotic system to
another.
Acoustic Coding
Perhaps the most intriguing characteristics of speech
perception concern the problematic relationship between
the perceived phonetic categories and the more or less
rich, pre-categorial sensory information that is the
carrier of such perception. Verbal communication involves
a series of conversions; at the hearer's end, it begins
with an acoustic stream which he converts into strings
of phonetic categories which, in turn, he converts
into semantic units, and so forth. There is little
structural resemblance between the acoustic information
and the abstract phonetic categories; the former is
thoroughly restructured, and excluded from consciousness.
Very little, if at all, of the acoustic information
remains available for direct introspection. Thus, for
instance, we can tell from introspection, with some
effort, that /s/ is "higher" than /S/ (cf.
figure 2); but it is quite impossible to tell from
introspection that the items in the sequence /ba, da,
ga/ differ from one another only in the onset frequency
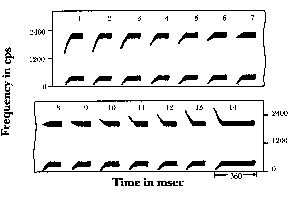
of the second formant transition (cf. figures 2, 6).
There is no one to one relationship between the segments
of perceived speech and the segments of the acoustic
signal that carries it. Rather, there is between the
two a mediating step of "complex coding".
Vowels consist of specific combinations of overtones,
called formants. A formant is a concentration of acoustic
energy within a restricted frequency region. With the
help of a device called spectrograph (or sonagraph),
these concentrations of energy can be converted into
patches of light and shade called spectrograms. In
speech spectrograms, three or four formants can usually
be detected. In the synthetic, hand-painted spectrograms
of figure 1, only the lowest two formants are represented.
Formants are referred to by numbers: F1, F2, etc.,
the first being the lowest in frequency, the next the
next higher, and so on (F0 refers to the "baseline",
the fundamental pitch). A formant transition is a relatively
rapid change in the position of the formant on the
frequency scale. A device called pattern-playback converts
hand-painted spectrograms into sound. This provides
the basis for what has proven to be a convenient method
of experimenting with the speech signal: it makes it
possible to vary those parameters that were estimated
to be of linguistic importance and subsequently test
the result by listening to the vocal output. In Figure
1, the steady-state formants are, by their different
positions on the frequency scale, the cues for the
vowels /i/ and /u/. We can see that for these vowels
there is a straightforward correspondence between acoustic
and phonetic segments.
But consider now the voiced stop /d/. To isolate the
acoustic cue for the segment, we should first notice
the transition of the lower (first) formant. That transition
is not specifically a cue for /d/; it rather tells
the listener that the segment is one of the voiced
stops, /b/, /d/, or /g/. [...] To produce /d/, instead
of /b/, or /g/, we must add the transitions of the
higher (second) formant, the parts of the pattern that
are encircled by the [dotted] line (Liberman, 1970:
307-308).

If we play back only the circled parts of the pattern,
we clearly hear what we would expect to, judging from
the appearance of the formant transition: an upward
glide in one case, and a rapidly falling whistle in
the other. When the whole pattern is played back, we
hear no glide or whistle, but the syllable /di/ or
/du/. One and the same phoneme is prompted, then, by
vastly different acoustic cues. In the case of /di/,
the transition rises from approximately 2200 cps to
2600 cps; in /du/, it falls from about 1200 cps to
700 cps. Furthermore, there is no way to cut the patterns
of Figure 1 so as to recover /d/ segments that can
be substituted one for the other, or to obtain some
piece that will produce /d/ alone. If we cut progressively
into the syllable from the right-hand end, we hear
/d/ plus either a vowel, or a nonspeech sound; at no
point will we hear only /d/. "This is so, because
the formant transition is, at every instant, providing
information about two phonemes, the consonant and the
vowel -- that is, the phonemes are transmitted in parallel"
(Liberman et al., 1967: 436). This is why the phenomenon
in question is called parallel transmission. Speech
perception has another distinctive characteristics,
called "categorial perception". I will quote
Glucksberg and Danks' brief summary of the phenomenon
(1975: 40--41).
Figure 2 Hand-painted spectrograms of the syllables ba, da, ga.
The ba--da--ga pitch continuum of F2 is divided into 14 steps instead of three.
The two parallel regions of black indicate regions of energy concentration, F1 and F2.
Notice that the onset frequency of F2 of da is higher than that of ba;
and the onset frequency of F2 of ga is higher than that of da.
In general, people can discriminate among a very large number of physical stimuli. For example, we can discriminate among approximately 1,200 different pitches, and among a wide variety of colors. We are also aware that such stimuli as pitches and colors vary continuously and smoothly along particular dimensions. Certain speech stimuli do not behave in this way (Liberman, Harris, Hoffman, & Griffith, 1957; Studdert-Kennedy, Liberman, Harris,& Cooper, 1970). Although the physical stimuli may vary continuously over a fairly wide range, we do not perceive this variation. Consider the continuous series of changes in the second formant of a simple English syllable, shown in Figure 2. These sound patterns produce the syllables [ba], [da], and [gal when fed into a speech synthesizer. The first three syllables are heard as [ba], the next six as [da], and the last five as [ga]. People discriminate extremely well between these three "categories," but do not hear the differences within each category (Mattingly et al., 1971). The three [b]'s all sound the same, even though there is continuous change along a single dimension. Between stimuli 3 and 4, listeners perceive a shift from [b] to [d]. This difference is always perceived as quite distinct, even though it is physically no more different than the difference between stimuli 2 and 3 or between 4 and 5.
Parallel transmission on the one hand and, on the other,
the fact that isolated transitions are heard as musical
sound or natural noise, whereas the same transitions
in the continuous stream of speech, even within a single
nonsense syllable, is heard as speech sounds, may direct
attention to some of the distinguishing marks of speech
perception; they seem to indicate that we have a speech
mode and a nonspeech mode of listening, which follow
different paths in the neural system.
I wish to illustrate these two modes of listening through two series of sound stimuli from an unpublished demo tape by
Terry Halwes. Listen to the series in figure 2, and see whether you hear the change from [ba] to [da], from [da] to [ga] occur suddenly.
| ba, da, ga |
Let us isolate the second formant transition, that piece of sound which differs across the series, and listen to just those sounds alone.
| Glides and whistles |
Most people who listen to that series report hearing what we would expect to, judging from the appearance of the formant transition: upward glides, and falling whistles
displaying a gradual change from one to the next. The perception of the former series illustrates the speech mode, of the latter series -- the nonspeech mode.
We seem to be
tuned, normally, to the nonspeech mode; but as soon
as the incoming stream of sounds gives the slightest
indication that it may be carrying linguistic information,
we automatically switch to the speech mode: we "attend
away" from the acoustic signal to the combination
of muscle movements that seem to have produced it (even
in the case of hand-painted spectrograms); and from
these elementary movements away to their joint purpose,
the phoneme sequence. In certain circumstances, in
what we might perhaps call the "poetic mode",
some aspects of the formant structure of the acoustic
signal may vaguely enter consciousness. As a result,
people may have intuitions that certain vowel contrasts
correspond to the brightness ~ darkness contrast, some
other to the high ~ low contrast, or that certain consonants
are "harder" than others. As a result, in
turn, poets may use more frequently words that contain
dark vowels, in lines referring to dark colors, mystic
obscurity, or slow and heavy movement, or depicting
hatred and struggle. At the reception end of the process,
readers have vague intuitions that the sound patterns
of these lines are somehow expressive of their atmosphere.
There is some experimental evidence for the assumption
that in certain instances pre-categorial acoustic information
(from the nonspeech mode) does reach -- subliminally
though -- awareness. What is more, people appear to
be capable of switching modes, by using different listening
strategies. Fricative stimuli seem to be especially
suited for the application of different strategies,
such that they may be perceived fairly categorially
in one situation but continuously in another (Repp,
1984: 287). Repp has investigated the possibility that
with fricatives, for instance, little training would
be necessary for acoustic discrimination of within-category
differences. Repeating the "categorial perception"
experiment, he employed an [s]--[S] continuum, followed
by a vocalic context. The success of his procedure
together with the introspections of the experienced listeners, suggested that the skill involved lay in perceptually segregating the noise from its vocalic context, which then made it possible to attend to its "pitch". Without this segregation, the phonetic percept was dominant. Once the auditory strategy has been acquired, it is possible to switch back and forth between auditory and phonetic modes of listening, and it seems likely [...] that both strategies could be pursued simultaneously (or in very rapid succession) without any loss of accuracy. These results provide good evidence for the existence of two alternative modes of perception, phonetic and auditory -- a distinction supported by much additional evidence (ibid., 307).
Repp's "auditory mode" does not abolish the
distinction between the speech mode and the nonspeech
mode. It merely provides evidence that even in the
speech mode some pre-categorial sensory information
is accessible, that is, that the poetic mode is possible.
In the context of the present inquiry, Repp's experiment
may suggest an additional crucial possibility. When
imitation of natural noises by speech sounds are concerned,
language-users may switch back and forth between auditory
and phonetic modes of listening, so that both strategies
could be pursued simultaneously (or in very rapid succession)
without any loss of accuracy. Such a listening strategy
would greatly enhance the onomatopoeic effect.
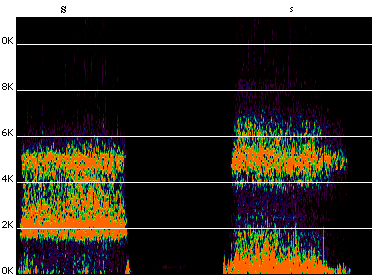
Figure 3 Sonograms of [S] and [s], representing the first and second formant,
and indicating why [s] is somehow "higher".
The information presented in figure 3 may give us a
clue to several effects regularly associated with these
speech sounds. First, we can distinctly see the first
and second formant of [s]; these formants are less
distinctly separated in [S]. Perception of the higher
second formant causes people to perceive [s] as higher.
The insufficient separation of the two formants of
[S] may arouse a sense of indistinctness which is translated
by many listeners into an intuition that it is somehow
"darker". Finally, outside speech, tones
and noises are distinguished by the regularity or irregularity
of sound stimuli. Tones repeat periodically the same
sound shapes; in noises, sound-stimuli are random.1
In language, vowels, semi-vowels, glides and liquids
are periodical; fricatives are transmitted by random
noises. The pre-categorial nonspeech sounds underlying
the fricatives [s] and [S] are more easily accessible
to introspection than those underlying the other fricatives;
that is why these two sounds so frequently serve in
words imitating natural noises.
In his paper on ecological acoustics, William Gaver (1993)
explores the acoustic basis of everyday listening as
a start toward understanding how sounds near the ear
can indicate remote physical events. In his view, students
of everyday listening must find the mapping between
the physics of the event and the attributes of the
resulting sound that serve as information to a listener.
"They must relate three levels of analysis, understanding
-- at some level of detail -- (a) the physics of the
event, (b) how that is reflected by the acoustics of
the sound, and finally (c) how that gives rise to the
perception of the event" (290). In the study of
onomatopoeia there must be an additional stage: pointing
out similar features between the pre-categorial sounds
that carry the imitating phonetic category and the
acoustics of the sound of the external event imitated.
The Cuckoo and the Nightingale
There is a parable by Izmailov about the cuckoo who
tells her neighbours in the province about the wonderful
song of the nightingale she heard in a far-away country.
She learned this song, and is willing to reproduce
it for the benefit of her neighbours. They all are
eager to hear that marvellous song, so the cuckoo starts
singing: "kukuk, kukuk, kukuk". The moral
of the parable is that that's what happens to bad translators
of poetry. The thesis of this paper is that Izmailov
does an injustice to the cuckoo (not to some translators).
When you translate from one semiotic system to another,
you are constrained by the options of the target system.
The cuckoo had no choice but to use cuckoo-language
for the translation. The question is whether she utilized
those options of cuckoo-language that are nearest to
the nightingale's song. After all, Izmailov himself
committed exactly the same kind of inadequacy he attributes
to the cuckoo. The bird emits neither the speech sound
[k] nor [u]; it uses no speech sounds at all. But a
poet (any poet) in human language is constrained by
the phoneme system of his language; he can translate
the cuckoo's song only to those speech sounds. His
translation will be judged adaquate if he chooses those
speech sounds that are most similar in their effect
to the cuckoo's call.
The issue at stake is the translation of perceived qualities
from reality to some semiotic system, or from one semiotic
system to another (in fact, the cuckoo's call too is
a semiotic system). The precision of translation depends
on how fine-grained are the sign-units of the target
system. If the target system is sufficiently fine-grained
and its nearest options are chosen to represent a source
phenomenon, it may evoke a perception that the two
are "equivalent". I propose to present the
problem through a well-known linguistic-literary phenomenon:
onomatopoeia. Onomatopoeia is the imitation of natural
sounds by speech sounds. There is an open set of infinite
noises in the world. But, as I said above, most
alphabets contain only twenty-something letters that
convey in any language a closed system of about fifty
(up to a maximum of 100) speech sounds. Nevertheless,
we tend to accept many instances of onomatopoeia as
quite adequate phonetic equivalents of the natural
noises. How can language imitate, with such a limited
number of speech sounds an infinite number of natural
noises? Take the bird called "cuckoo". The
cuckoo's name is said to have an onomatopoeic origin:
it is said to imitate the sound the bird makes, and
the bird is said to emit the sound [kukuk]. As I suggested,
the bird emits neither the speech sound [k] nor [u];
it uses no speech sounds at all. It emits two continuous
sounds with a characteristic pitch interval between
them, roughly a minor third. These sounds are continuous,
have a steady-state pitch and an abrupt onset. I have
hypothesized that the overtone structure of the steady-state
sound is nearest to the formant structure of a rounded
back vowel, and the formant transitions indicating
a [k] before an [u]. That is why the name of this bird
contains the sound sequence [ku] in some languages.2
In human language, European languages at least, pitch
intervals are part of the intonation system, not of
the lexicon. Consequently, the pitch interval characteristic
of the cuckoo's call is not included in the bird's
name (the lexicon is not sufficiently "fine-grained"
for the pitch interval).
In order to test these hypotheses, I took the European
cuckoo's song (from a tape issued by the Israeli Nature
Conservation Association) and submitted it to an instrumental
analysis, comparing it to three cardinal vowels, the
phonetic [i], [a] and [u] (included in the phonetic
application package "SoundScope"). There
is plenty of background noise in the cuckoo recording,
and I could not obtain a usable spectrogram. But my
phonetic application offers an option to extract the
formants of the speech sounds. A comparison between
the first two "formants" of the cuckoo's
call and the cardinal vowels yielded illuminating results
(see figure 4).3
Listen to the Europen cuckoo's call and the phonetic i-a-u vowels
| kuku | i-a-u |

Figure 4 The upper window presents the the first and second formant of the cuckoo's song
and of the phonetic vowels i-a-u; the lower window presents their waveform.
In the upper window of figure 4, the first formant of
[i], [u], and [kuku] form straightish horizontal lines
between 0 and 500 Hz; the first formant of [a] crinkles
around 1000 Hz, slightly touching the second formant.
The first "formant" of the cuckoo's call
looks very much like that of the [i] and the [u] both
in shape and frequency range (though more perfectly
horizontal), and very much unlike that of the [a].
The second "formant" of the cuckoo's song
is less regular than that of the [a] and the [u], but
displays similar tendencies and is smeared over a roughly
similar (but somewhat higher) pitch range. Thus, in
harmony with my hypothesis, the overtone structure
of the cuckoo's song displays greater resemblance to
the [u] than to the other two cardinal vowels. My second
hypothesis, however, has been bluntly refuted: there
is no part in the cuckoo's song that sounds like [k];
we hear something more like [huhu]. Nor is there any
sign of [k] in the computer's output. Before tackling
this problem, let us have a look at the pitch contours
extracted from the recordings of the cuckoo's song
and the cardinal vowels (figure 5).
The first observation to be made is that the two couldn't
be pasted in the same window: the fundamental frequency
of the cuckoo's call is about 5--6 times (!) higher
than that of the vowels spoken by a male speaker. It
reaches up to almost 780 Hz, and reaches down to exactly
580 Hz, whereas the vowels' intonation contours in
figure 5 reach up to about 135 Hz, and down to about
95 Hz (the typical male voice range is specified in
the application as 80--150 Hz; the typical female range
as 120--280 Hz). The remarkable thing to notice is
that in spite of this enormous difference of pitch,
the cuckoo's call and the vowel [u] are perceived as
equally "dark". This happens because the
perceived "darkness" is determined not by
their fundamental pitch, but by their overtone structure,
which we have found to be similar.
The upper windows present the pitch contours
of the cuckoo's song 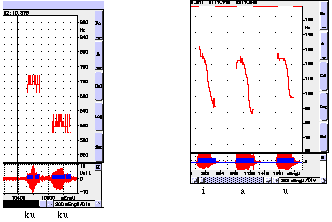
Figure 5
and of the phonetic vowels i-a-u
spoken by a male;
the lower windows present their
waveform.
I have said that pitch countour does not belong to the
lexicon of human speech, but to its intonation system.
But, as figure 5 indicates, the pitch contours of the
cuckoo's call and those of the spoken vowels tend to
be very dissimilar. The intonation contour of an isolated
vowel tends to move over a considerable pitch range,
and the perceived pitch of such a vowel is usually
unpredictable. The cuckoo's song, by contrast, abruptly
begins at a steady-state perceived pitch. I submit
that this is the abruptness we perceive at the onset
of the cuckoo's song, indicated by an abrupt voiceless
plosive in human onomatopoeia. The voiceless plosive
contributes to the perceived similarity only the abstract
quality abruptness. Thus, the cuckoo's abrupt pitch
onset is not translated in human lexicon to a similar
abrupt pitch onset (and cannot be lexicalized as such),
but to an abruptly articulated consonant, which has
nothing to do with pitch. Now there are at least three
voiceless plosives in human language, [p], [t] and
[k]. Why is it that precisely the [k] is perceived
in several languages as suitable to reproduce the cuckoo's
song, and not the other ones? There are two possible
answers to this question. First, phonetically, [p]
and [t] are "diffuse" consonants, [k] is
characterised as "compact", that is, more
abrupt. Second, there is the problem of co-articulation:
[u] is a backvowel, and as such it is more easily co-articulated
with the velar [k] than with the dental [t] or the
bilabial [p]. To understand better the nature of this
co-articulation, the reader is invited to pronounce
the words "kill" and "call". He
will notice that in the latter, before the back vowel,
the [k] is pronounced at a much lower point of the
vocal track.
Now the cuckoo's call is sometimes translated to another
semiotic system as well: the sound of a recorder, or
some other wind instrument -- in Haydn's (or Leopold
Mozart's?) "Toy Symphony", for instance.
Various recordings use various instruments to play
the cuckoo's part; so it may be of little help to analyze
the overtone structure of their sounds. The onset of
the sound played on these instruments is sometimes
abrupt too, though in some performances it sounds more
like a [h]. The player may articulate the abrupt onset
with the tip of the tongue touching the teethridge,
producing "tu-tu" as it were. Unlike the
lexicon of human language, this semiotic system does
provide the option to produce the pitch interval of
a minor third. It produces the steady-state sounds
with an external instrument, from the lips outward;
so, co-articulation does not confine the abrupt gesture
(when present) to [k]; the [t] is no less convenient,
perhpas even more. Thus, the two semiotic systems constrain
the reproduction of the cuckoo's natural call in different
ways, as determined by their respective limitations.
They offer different sign vehicles for it, and different
syntax for the combination of these sign vehicles.
None of these systems offers the exact sounds for reproducing
the cuckoo's call; in each system one must choose the
options that are nearest to the target sound. That
is the best what semiotic systems can offer for the
representation of qualities perceived in reality or
in another semiotic system. A sound imitation is perceived
as an equivalent of the imitated reality if the target
semiotic system is sufficiently fine-grained in the
relevant respects; and the most relevant options of
the semiotic system are chosen.
Returning now to the cuckoo and the nightingale, we
should not condemn the cuckoo's imitation of the nightingale's
song for translating it into cuckoo-language; we should,
rather, judge its adequacy according to whether it
does or does not choose those options of cuckoo-language
that are nearest to the nightingale's song.
The Click of the Clock
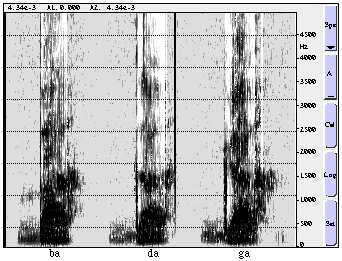
I have spoken above of degrees of encodedness. While
in the [s--S] distinction respondents can tell by conscious
introspection that the former is somehow higher than
the latter, in the [ba, da, ga] series, they can't
tell that all the difference between them is a rise
in the onset frequency of the second formant transition
(see figures 2, 3, and 6). However, when asked to order
these nonsense syllables in the order of their relative
"metallicness", they (1) don't say they don't
know what I am talking about, and (2) they tend to
judge [ba] as the least metallic of the three, and
after some hesitation, to judge [ga] as the most metallic
of them. In such issues I don't usually look for a
straightforward structural resemblance between [ga]
and "metallicness", but rather proceed in
three steps: (1) I collect empirical evidence for intuitions
of respondents; (2) concerning these intuitions, try
to determine what phonetic scale is perceived as analogous
to what nonphonetic scale (e.g., [i-u] is analogous
to both "high-low" and "bright-dark");
and (3) attempt to explain why precisely the "high"
and "bright" poles are matched with the phonetic
[i]-pole rather than the other way around.
Now, as for the analogy between the [ba, da, ga] series
and the [+/-metallic] spectrum, I was rather stammering
at the third stage, and it was Gaver's (1993) paper that gave
me the systematic clue for an explanation: "The
sounds made by vibrating wood decay quickly, with low
frequencies lasting longer than high ones, whereas
the sounds made by vibrating metal decay slowly, with
high-frequency showing less damping than low ones.
In addition, metal sounds have partials [=overtones
-- R.T.] with well-defined frequency peaks, whereas
wooden sound partials are smeared over frequency space"
(pp. 293-294). Even if the sound structure of vibrating
metals is quite unlike the sound structure of the voiced
plosive [g], this might be sufficient to warrant the
matching of the [ga]-pole of the phonetic sequence,
with the "metallic"-pole of the [+/-metallic]
spectrum. Now this matching may be reinforced by the
opposition "well-defined frequency peaks"
~ "smeared over frequency space", which may
be perceived as corresponding to the compact ~ diffuse
opposition in the traditional phonetics domain, characterising
[g] ~ [b, d]. Again, these may be different kinds of
compactness and diffuseness, but sufficient to suggest
the matching of the [+metallic]-pole of one scale with
the [ga]-pole rather than the [ba]-pole of the other.
There is nothing metallic in the velum, the place of
articulation of the [k]. It is the acoustic features
pointed out in the preceding paragraph that render
[k] more metallic than [b] or [d]. This can explain
why we hear the clock tick-tocking rather than, e.g.,
tip-topping. The [k] is better suited than the [p]
or the [t] to imitate the metallic click of the clock.
Figure 6 Spectrograms of the syllables ba, da, ga, in natural speech.
We have explained two crucial things about onomatopoeia:
first, that behind the rigid categories of speech sounds
one can discern some rich pre-categorial sound information
that may resemble natural sounds in one way or other;
and it is possible to acquire auditory strategies to
switch back and forth between auditory and phonetic
modes of listening; and second, that certain natural
noises have more common features with one speech sound
than with some others.
But we have still not explained two additional findings
which, in fact, appear to be two sides of the same
coin. First, we have said that there is an infinity
of natural noises, but only about 50--100 speech sounds
in any given language. And second, we have found that
the same speech sound [k] may imitate some metallic
noises, or indicate an abrupt onset (not necessarily
metallic) of the word that imitates the natural sound
"ku-ku". These two issues are intimately
related. Every speech sound is a bundle of features.
In different contexts we may attend to different features
of the same sound. When the context changes from, say,
kuku to, say, ticktock, we attend away from one feature
(abruptness) to another (metallicness). I claim that
this ability to attend away from one feature to another
is similar to what Wittgenstein called "aspect
switching". In this way, the closed and limited
system of the speech sounds of a language may offer
an indefinite number of features to be exploited
for the imitation of natural sounds.
Relevant features can be multiplied indefinitely, and
discover unexpected phonetic or phonological features.
Let us consider a minimal pair that can illustrate
this. In Hebrew, metaktek means "ticktocking";
we attend to the repeated voiceless plosives and perceive
the word as onomatopoeic. metaktak, by contrast,
means "sweetish". In Hebrew, the repetition
of the last syllable is lexicalized, suggesting "somewhat
(sweet)". A wide range of such "moderate"
adjectives can be derived in this way from "main-entry"
adjectives: hamatsmats (sourish) from hamuts (sour),
adamdam (reddish) from adom (red), yerakrak (greenish)
from yarok (green), and so forth. The meaning directs
our attention to this redoubling of the syllable, and
we attend away from the acoustic features of the specific
consonants.
Fine-Grainedness
The notion "fine-grained" needs some elaboration.
My claim is that the delicacy of the units of the target
system has a crucial influence on the generation of
effects in sound symbolism. The cuckoo's semiotic system
is, obviously, not sufficiently fine-grained for imitating
the nightingale's song. Human languages may differ
in the distinctions they make between speech sounds:
some languages make finer distinctions in one respect;
some -- in other respects. A phonological system that
has the dental stop [t] as well as the dental fricative
[s] is more fine-grained in that respect than a system
that has only [t]; and a system that has in between
the stop and the fricative the affricate [ts] is even
more fine-grained. For brevity's sake, I will consider
here similar expressive sound gestures in German, Hebrew
and English, as constrained by their respective phonological
systems. In chapter 2 of my book (Tsur, 1992), I put
forward a model for expressive sound patterns, based
on Roman Jakobson's (l968) developmental model of language
acquisition, and on the acoustic structure of the speech
sounds. I claimed that speech sounds that are late
acquisitions of the infant have greater expressive
force than the early acquisitions. Among the late acquisitions,
continuous, periodic sounds are deemed "pleasant"
(as French --on and --eur); abrupt (noncontinuous)
sounds are typically deemed as unpleasant. Affricates
are late acquisitions and abrupt. German [pf] is acquired
only after the acquisition of the plosive [p] and the
fricative [f]. English and Hebrew infants stop short
of acquiring this sound. German, Hebrew and Hungarian
[ts] is acquired only after the acquisition of the
plosive [t] and the fricative [s]. In German there
is an interjection "pfuj", expressing disgust
(imitating a gesture of the lips, as though "spitting").
In Hebrew and English, this bilabial affricate does
not exist; so, these languages are confined to the
nearest bilabials, for the same sound gesture: in Hebrew
"fuya"; in English "fie". The dental
affricate [ts] does exist in Hebrew (acquired after
[t] and [s]); indeed, this affricate occasionally serves
in Hebrew to express displeasure.
Spitting is a gesture of the lips serving to expel harmful food and other unwanted substances. So it became a gesture expressive of disgust. In human language, such an eliminating gesture is frequently imitated by some word beginning with a bilabial phoneme. According to Jakobson, later aquisitions (such as affricates) have greater expressive potential than earlier acquisitions (such as plosives or fricatives). Thus German, whose phonological system contains the affricate [pf] is fine-grained enough to use an interjection that is most effective in expressing disgust [pfuj]. The word "pfeifen" (to whistle, to pipe), by contrast, directs attention to a different aspect of the same lip gesture: the lips are used to produce the whistling sound, or to blow the instrument. English and Hebrew phonology is less fine-grained in this respect (the affricate [pf] does not exist in them); so, they can only approximate it: are forced to have recourse to some bilabial that is an earlier acquisition. Thus, for instance, the English word akin to "pfeifen" is "pipe" -- involving two bilabial plosives. The Hebrew word corresponding to "whistle", "letsaftsef" (![]() ), is a most interesting case of choosing the nearest option which a semiotic system can offer. [f] is a bilabial fricative; no affricate is available in Hebrew at this place of articulation, but the distinctive feature [+ AFFRICATE] occurs in the other consonant, ts. Reduplication of the syllable in the word "letsaftsef" relates it to the transition from the child's babbling stage to the arbitrary use of verbal signs. "By the repetition of the same syllable [papa, mama, tata, nana -- R.T.], children signal that their phonation is not babbling but a verbal message" (Jakobson and Waugh, 1979: 196). Victoria Fromkin (1973) pointed out that in "slips of the tongue" sometimes distinctive features exchange places, or move from one speech sound to another. In my recent book (Tsur, 2003) I mentioned the example of a young Hebrew poet who inadvertantly substituted the Hebrew word "mefagrim" (mentally retarded) for "mevakrim" (critics). In this instance, the features [+ VOICED] and [- VOICED] changed places. Such slips of the tongue indicate that transfer of the feature [+ AFFRICATE] in "letsaftsef" to the preceding consonant does have psychological reality.
), is a most interesting case of choosing the nearest option which a semiotic system can offer. [f] is a bilabial fricative; no affricate is available in Hebrew at this place of articulation, but the distinctive feature [+ AFFRICATE] occurs in the other consonant, ts. Reduplication of the syllable in the word "letsaftsef" relates it to the transition from the child's babbling stage to the arbitrary use of verbal signs. "By the repetition of the same syllable [papa, mama, tata, nana -- R.T.], children signal that their phonation is not babbling but a verbal message" (Jakobson and Waugh, 1979: 196). Victoria Fromkin (1973) pointed out that in "slips of the tongue" sometimes distinctive features exchange places, or move from one speech sound to another. In my recent book (Tsur, 2003) I mentioned the example of a young Hebrew poet who inadvertantly substituted the Hebrew word "mefagrim" (mentally retarded) for "mevakrim" (critics). In this instance, the features [+ VOICED] and [- VOICED] changed places. Such slips of the tongue indicate that transfer of the feature [+ AFFRICATE] in "letsaftsef" to the preceding consonant does have psychological reality.
This conception of adequacy in translating from one
semiotic system to another can be applied most profitably
to literary effects. We accept a translation from one
semiotic system to another as adequate (e.g., the representation
of the felt quality of a mystic experience in the verbal
medium), if the target system is sufficiently fine-grained;
and if the options most similar to the source experience
are chosen. When we print a picture, the higher the
resolution (that is, the more fine-grained the system),
the better is its resemblance to the original. And
when we record music, the finer the metallic grains
on the tape, the higher the fidelity of music achieved.
We will expect the best quality afforded by our system,
even if we may adapt ourselves to lower resolution
pictures, or lower fidelity music. We may imagine that we
hear the bass sounds of a symphony on the speaker of
a small portable radio; but the same sound quality
would be unacceptable to us on a high quality stereo
system.
Footnotes
1. Periodic sounds have been described (May and Repp, 1982: 145)
as "the recurrence of signal portions with similar
structure", whereas aperiodic stimuli have a "randomly
changing waveform", that "may have more idiosyncratic
features to be remembered". The recurring signal
portions with similar structures may arouse in the
perceiver a relatively relaxed kind of attentiveness
(there will be no surprises, one may expect the same
waveform to recur). Thus, periodic sounds are experienced
as smoothly flowing. The randomly changing waveforms
of aperiodic sounds, with their "idiosyncratic
features", are experienced as disorder, as a disruption
of the "relaxed kind of attentiveness". Thus,
aperiodic sounds are experienced as harsh, strident,
turbulent, and the like. [Back]
2. My evidence for this generalization is anecdotal. It is true for German, English, French, Hungarian and Hebrew cuckoos (these are the languages with which I am familiar; judging from Izmailov's parable, this is the case in Russian too). I am not in a position to collect the information from African and Amer-Indian languages. In the cuckoo's case there may be some proved mutual influence among these languages. But then we must explain why, when the name is not of onomatopoeic origin, there is little influence between them. English "nightingale", for instance, resembles only its German counterpart; in French it is "rossignol", in Hungarian
"fülemüle", in Hebrew "zamir". After having written the foregoing comment, I happened to meet a young Chinese woman from Beigin, and asked her what was the Chinese word for "cuckoo". She said it was [pu-ku]. The [k] sounded very deep down the throat; and there was a falling-rising tone on the second syllable, that had nothing to do with the characteristic interval of the cuckoo song. I am indebted to Sinologist Lihi Laor, who told me that in Chinese the +/-voiced opposition doesn't exist, only the +/-aspirated opposition. My impression that it was a deep [k] indicates that it is an unaspirated [k]. In fact, both plosives in this word are unvoiced and unaspirated. To her great surprise, her native speaker colleagues of various Chinese dialects all came up with exactly the same word. One might further speculate that the deep [k] may corroborate my co-articulation hypothesis; the unaspirated plosives may corroborate my abruptness hypothesis. The falling-rising tone on [ku] suggests that even Chinese cannot lexicalize the minor third interval; it is the linguistic constraints that determine the tone.
[back]
3. When you paste the cuckoo's sound into
the vowels' window (or vice verza), the formants' graph
is exactly preserved, but the sound undergoes considerable
distortion. [back]
References
Tsur, Reuven (2003) On The Shore of Nothingness: Space, Rhythm, and Semantic Structure in Religious Poetry and its Mystic-Secular Counterpart -- A Study in Cognitive Poetics. Exeter: Imprint Academic.
![]()
Back to home page
Back to "Occasional Papers"
This page was created using TextToHTML. TextToHTML is a free software for Macintosh and is (c) 1995,1996 by Kris Coppieters