Fleiss' kappa

Fleiss' kappa is a variant of Cohen's kappa, a statistical measure of inter-rater reliability. Where Cohen's kappa works for only two raters, Fleiss' kappa works for any constant number of raters giving categorical ratings (see nominal data), to a fixed number of items. It is a measure of the degree of agreement that can be expected above chance. Agreement can be thought of as follows, if a fixed number of people assign numerical ratings to a number of items then the kappa will give a measure for how consistent the ratings are. The kappa, 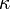 , can be defined as
, can be defined as
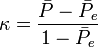
The factor 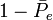 gives the degree of agreement that is attainable above chance, and
gives the degree of agreement that is attainable above chance, and 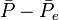 gives the degree of agreement actually achieved above chance. The statistic takes values between 0 and 1, where a value of 1 means complete agreement.
gives the degree of agreement actually achieved above chance. The statistic takes values between 0 and 1, where a value of 1 means complete agreement.
An example of the use of Fleiss' kappa may be the following: Consider fourteen psychiatrists are asked to look at ten patients. Each gives one of possibly five diagnoses to each patient. The Fleiss' kappa can be computed from the data matrix (see example below) to show the degree of agreement between the psychiatrists above the level of agreement expected by chance. Fleiss' kappa has benefits over the standard Cohen's kappa as it works for multiple raters, and it is an improvement over a simple percentage agreement calculation as it takes into account the amount of agreement that can be expected by chance.
Contents |
[edit] Definition
Let N be the number of subjects, n the number of ratings per subject, and k the number of categories into which assignments are made. The subjects are indexed by i = 1, ... N and the categories are indexed by j = 1, ... k. Let nij, represent the number of raters who assigned the i-th subject to the j-th category.
First calculate pj, the proportion of all assignments which were to the j-th category:
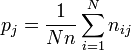
Now calculate 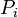 , the extent to which raters agree for the i-th subject:
, the extent to which raters agree for the i-th subject:
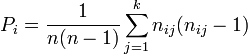
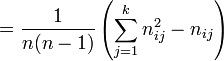
Now compute 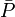 , the mean of the
, the mean of the 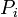 's, and
's, and 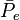 which go into the formula for :
which go into the formula for :
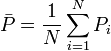
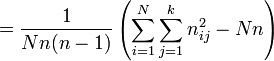
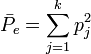
[edit] Worked example
| 1 | 2 | 3 | 4 | 5 |
| |
|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 14 | 1.000 |
| 2 | 0 | 2 | 6 | 4 | 2 | 0.253 |
| 3 | 0 | 0 | 3 | 5 | 6 | 0.308 |
| 4 | 0 | 3 | 9 | 2 | 0 | 0.440 |
| 5 | 2 | 2 | 8 | 1 | 1 | 0.330 |
| 6 | 7 | 7 | 0 | 0 | 0 | 0.462 |
| 7 | 3 | 2 | 6 | 3 | 0 | 0.242 |
| 8 | 2 | 5 | 3 | 2 | 2 | 0.176 |
| 9 | 6 | 5 | 2 | 1 | 0 | 0.286 |
| 10 | 0 | 2 | 2 | 3 | 7 | 0.286 |
| Total | 20 | 28 | 39 | 21 | 32 | |
 |
0.143 | 0.200 | 0.279 | 0.150 | 0.229 |
In the following example, fourteen raters (n) assign ten subjects (N) to a total of five categories (k). The categories are presented in the columns, while the subjects are presented in the rows.
[edit] Data
See table to the right.
N = 10, n = 14, k = 5
Sum of all cells = 140
Sum of = 3.780
[edit] Equations
For example, taking the first column,
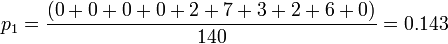
And taking the second row,
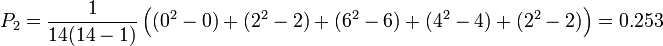
In order to calculate , we need to know the sum of Pi,
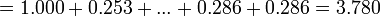
Over the whole sheet,
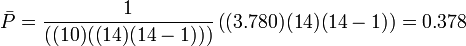
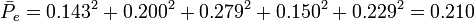
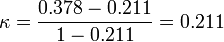
[edit] Significance
Landis and Koch Template:Ref give the following table for interpreting the significance of the κ value. This table is however no means universally accepted as a guide for interpreting the value. It has been noted that this benchmark may be more harmful than helpfulTemplate:Ref, as the number of categories and subjects will affect the magnitude of the value. The kappa will be higher when there are fewer categories. Template:Ref
| κ | Interpretation |
|---|---|
| < 0 | No agreement |
| 0.0 — 0.19 | Poor agreement |
| 0.20 — 0.39 | Fair agreement |
| 0.40 — 0.59 | Moderate agreement |
| 0.60 — 0.79 | Substantial agreement |
| 0.80 — 1.00 | Almost perfect agreement |
[edit] See also
[edit] Notes
- Template:Note Landis JR, Koch GG (1977) "The measurement of observer agreement for categorical data" in Biometrics 33:159-74
- Template:Note Gwet K (2001) Statistical Tables for Inter-Rater Agreement. (Gaithersburg : StatAxis Publishing)
- Template:Note Sim J, Wright CC (2005) "The Kappa Statistic in Reliability Studies: Use, Interpretation, and Sample Size Requirements" in Physical Therapy 85:257-68
[edit] References
- Fleiss JL (1971) Measuring nominal scale agreement among many raters. Psychological Bulletin 76:378--382
[edit] Further reading
- Fleiss JL, Cohen J (1973) The equivalence of weighted kappa and the intraclass correlation coefficient as measures of reliability" Educational and Psychological Measurement 33:613-9
- Fleiss JL (1981) Statistical methods for rates and proportions. 2nd ed. (New York: John Wiley) pp. 38-46
[edit] External links
- Kappa: Pros and Cons contains a good bibliography of articles about the coefficient.
| |
Some content on this page may previously have appeared on Citizendium. |