Question 1
Show an example of an MDP with n states and two actions, where
the Policy Iteration algorithm requires n iterations to converge to the
optimal policy.
(Open problem: Show an example that requires more than
n iterations.)
Question 2
Let ![]() and
and ![]() be two deterministic
stationary policies for a given MDP M.
Construct a new policy
be two deterministic
stationary policies for a given MDP M.
Construct a new policy ![]() in the following way,
in the following way,
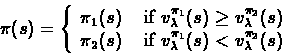
Question 3
We can use the approximate value function, computed in the Value Iteration algorithm, to define a policy.
Prove that if the number of states and actions are finite, then after a finite number of iterations this policy equals the optimal policy and never changes.
Give an example of an MDP where the number of iterations until the
policy defined by value iteration converges to the optimal policy is
at least
![]() .
(Hint: build an MDP such that from the start state you can branch two
two different states, once you reach a state you remain in it.)
.
(Hint: build an MDP such that from the start state you can branch two
two different states, once you reach a state you remain in it.)
The homework is due in two weeks