Back to home page
Back to "Occasional Papers"
Back to Contents page
Reuven Tsur
Size–Sound Symbolism Revisited
Preliminary
In many of my writings I have argued that poetic images
have no fixed predetermined meanings. In my 1992 book
What Makes Sound Patterns Expressive? -- The Poetic
Mode of Speech Perception (originally published in
1987) I propounded the view that speech sounds do not
have fixed predetermined symbolic values either. Poetic
images as well as speech sounds are clusters of features,
each of which may serve as ground for some combinational
potential. The resulting combinations of images and
speech sounds give rise to figurative meanings and
sound symbolism. Unforeseen contexts may actualise
unforeseen potentials of images and speech sounds.
Language users may shift attention from one potential
to another in the same speech sound or poetic image,
and realise new figurative meanings and sound-symbolic
qualities. Thus, the handling of figurative language
and sound symbolism in poetry is governed by a set
of homogeneous principles. The acquisition and use
of language require considerable creativity. This creativity
is heightened and turned to an aesthetic end in the
writing and understanding of poetry. In my writings
I have explored the sources of these potentials, and
how human intuition handles them in generating poetic
qualities.
In this way, a sophisticated interplay between sound
and meaning is generated. Relevant features can be
multiplied indefinitely, and one may discover unexpected
phonetic or phonological features. In my 2001 paper
"Onomatopoeia: Cuckoo-Language and Tick-Tocking:
The Constraints of Semiotic Systems" I consider
a minimal pair that can illustrate this. In Hebrew,
metaktek means "ticktocking"; we attend
to the repeated voiceless plosives and perceive the
word as onomatopoeic. metaktak, by contrast, means
"sweetish", derived from matok (sweet). In
Hebrew, the repetition of the last syllable is lexicalized,
suggesting "somewhat (sweet)". A wide range
of such "moderate" adjectives can be derived
in this way from "main-entry" adjectives:
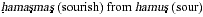 , adamdam (reddish)
from adom (red), yerakrak (greenish) from yarok
(green), and so forth. Hebrew slang even derives gevarbar
("somewhat man") from
, adamdam (reddish)
from adom (red), yerakrak (greenish) from yarok
(green), and so forth. Hebrew slang even derives gevarbar
("somewhat man") from 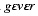 (man). The meaning
directs our attention to this redoubling of the syllable,
and we attend away from the acoustic features of the
specific consonants. Benjamin Hrushovski (1968; 1980)
pointed out that the sibilants have different (even
opposite) effects in "When to the sessions of
sweet silent thought / I summon up remembrance of things
past" and in "And the silken, sad uncertain
rustling of each purple curtain". In my book I
explore the different aspects of the sibilants that
may generate such conflicting effects. In the former
quote, meaning components related to "silent"
activate one set of aspects; in the latter, meaning
components related to "rustle" activate another
set. This is what Wittgenstein (1976) called "aspect-switching".
(man). The meaning
directs our attention to this redoubling of the syllable,
and we attend away from the acoustic features of the
specific consonants. Benjamin Hrushovski (1968; 1980)
pointed out that the sibilants have different (even
opposite) effects in "When to the sessions of
sweet silent thought / I summon up remembrance of things
past" and in "And the silken, sad uncertain
rustling of each purple curtain". In my book I
explore the different aspects of the sibilants that
may generate such conflicting effects. In the former
quote, meaning components related to "silent"
activate one set of aspects; in the latter, meaning
components related to "rustle" activate another
set. This is what Wittgenstein (1976) called "aspect-switching".
I wish to point out an additional issue, crucial for
an understanding of how sound symbolism works. The
Haskins Laboratories researchers distinguish between
a speech mode and a nonspeech mode of aural perception,
which follow different paths in the neural system.
In the nonspeech mode we listen to a stream of auditory
information in which the shape of what is perceived
is similar to the shape of the acoustic signal; in
the speech mode we "attend away" from the
acoustic signal to the combination of muscular acts
that seem to have produced it; and from these elementary
movements away to their joint purpose, the abstract
phoneme sequence. In this mode, all the rich precategorial
sensory information is shut out from awareness (listen
in my 2001 article to the
"ba-da-ga" series and the series of glides and whistles after Figure
2). In verbal communication it is the abstract phoneme
that counts, not the precategorial sound stream or
the articulatory gestures that led to the abstract
category. There is, however, experimental literature
that gives evidence that some of the rich precategorial
sensory information is subliminally perceived. I have
claimed that there is also a "poetic mode"
of speech perception, in which emotional and perceptual
qualities are generated when the precategorial auditory
information is available for combination with meaning
components. In the Hebrew word for "ticktocking"
the meaning directs attention to the sensory information
underlying the voiceless plosives; in the Hebrew word
for "sweetish" it directs attention away,
to an abstract lexical model.
The present paper was prompted by three chapters, by
John Ohala, Eugene Morton, and Gérard Diffloth,
in the mind-expanding collection of essays Sound Symbolism
(Hinton, Nichols and Ohala eds., 1994). In the light
of these essays I will recapitulate two issues from
the chapter "Some Spatial and Tactile Metaphors
for Sounds" of my above-mentioned book: the relation
between sound frequency and the size of the body that
produced it; and the relation between "high"
and "low" vowels and the suggested size of
their referents. The former may account for the rise
of certain crucial potentials active in the latter.
Sound Symbolism and Source's Size
Sounds can be located along dimensions whose extremes
are marked by spatial notions as low~high, thick~thin
or space-related notions as heavy~light, and the like.
These dimensions seem to be correlated in certain meaningful
ways. There is plenty of anecdotal as well as carefully
controlled experimental evidence that intuitions concerning
the "spatial" as well as the "tactile
qualities" of sound are fairly consistent from
observer to observer, and sometimes even from culture
to culture. Some such experiments have been reported
by Roger Brown in his classic of psycholinguistics
(Brown, 1968: 110-154). The whole chapter testifies
to Brown's usually brilliant insights and subtle ways
of analysis. Here, however, I am going to quote only
two passages with which I disagree.
A concept like "boulder" is referred to rocks
and stone and, in comparison, judged to be "heavy",
"large", "thick", and "wide".
These terms are directly applicable to boulders. However,
boulders have no voices. Where, then, does the concept
belong on the "bass-treble" or "loud-soft"
scales? We cannot doubt the answer. If Disney were
to give a boulder a voice it would be "bass"
and "loud" in contrast to the piping of a
pebble. This could be a mediated association: a boulder
must have a bass voice because creatures that do have
bass voices are usually heavy and boulders are heavy.
It is not necessary to assume that there is any subtle
inter-sensory quality found in boulders and bass voices.
Subjects in the study of Brown et al., felt that "thick"
and "thin" simply do not apply to voices.
However, "loud" and "resonant"
do. Now thick people and animals and violin strings
are usually loud and resonant. So, if the subject is
required to guess, he will call the loud and resonant
voice "thick". This need not be because the
voice shares some inter-sensory quality with the visual
or tactile apprehension of thickness. It could be because
the voice is loud and creatures who have loud voices
are usually thick, a mediated association (152-153).
The cognitive approach to Man, of which Brown is one
of the most outstanding exponents, tends to regard
such explanations as "mediated associations"
as the last resort of the scientist, where all structural
explanations fail. Now, what seems to be wrong with
the "mediated associations" theory is that
it reverts to a rather strong version of associationist
theory, assuming that people in various cultures have
been uniformly conditioned by external conditions.
It seems to be all too easy to invent some mediating
story that appears to be pretty convincing, until one
becomes aware of not less convincing counter-examples.
Thus, for instance, red colour is felt to be "warm",
whereas blue is felt to be "cold"; this feeling
is not culture-dependent, and thus cannot be explained
by cultural conditioning. Now there is a rather widely
accepted explanation, that fire is red in all cultures
whereas the blue sea is relatively cold in all cultures.
However, the blue sky on a tropical (or even European)
summer-noon is not exactly associated with cold. The
sun, on the other hand, at its hottest, would be associated
with gold rather than red, whereas red would be associated
with the setting rather than with the shining sun.
I submit that bass voices are perceived as thicker than
soprano voices, not because creatures that do have
bass voices are usually thick and heavy, but, precisely,
because "they share some inter-sensory quality
with the visual or tactile apprehension of thickness"
(I happen to know quite a few thick and heavy opera
singers who have tenor or even coloratura soprano voices).
Whereas the relationship between thick people and bass
voices appears to be quite incidental, the relationship
between thick violin strings and "thick"
and "low" sounds seems to have good physical
reasons. Sounds are vibrations of the air or some other
material medium. The thicker the string, other things
being equal, the slower and wider the vibrations. (Not
so with singers: when they get fatter or thinner, their
voice range and voice quality remains essentially unchanged).
There are, then, at least three physical dimensions
of sound that are analogous and co-varying: slow~fast,
wide~narrow, and thick~thin. The first two pairs of
adjectives describe the vibrations, the third pair
describes the strings (if there be any) that may be
causally related to the first two. It should be noted,
however, that whereas the thick~thin pair characterizes
the source of the sound, and may be extended to the
distal "stimulus", the perceived sound, only
by way of some conditioned reflex -- the slow~fast
and the wide~narrow pairs characterize the "proximal
stimulus" that actually hits the membrane of the
ear and is directly experienced. Michael Polányi
(1967: 13) argues that the meaning of the "proximal
term of tacit knowledge" (and, one might add,
the qualities of perception) are typically displaced,
away from us, to the distal term. Phenomenologically,
the relative frequency and width of sound vibrations
are experienced as their relative "height"
and "thickness", respectively.
As for the thick~thin characterization of sounds, an
additional observation seems to be pertinent. The sounds
we usually hear do not consist of fundamentals only,
but of overtones too. Since the range of frequencies
audible to the human ear is limited, and since there
are no "undertones", the lower the fundamental,
the greater the number of overtones that are within
the hearing range of the human ear. Thus, when we strike
a key near the left end of the piano keyboard, we perceive
a "thick aura" of overtones around the sound
that is absent from the sounds produced by striking
the keys near the right end (notice, by the way, that
in spite of the left-to-right arrangement of the keyboard,
we perceive the piano sounds as "low" or
"high" rather than "left-wing"
or "right-wing" as would be predicted by
a mediated-association theory).
Recently I encountered a most fruitful alternative to
the "mediated association" principle, which
integrates Brown's and my approach, that is, assumptions
regarding body-size with assumptions regarding the
size of articulatory organs and width of vibration
in relating small size with high sounds, and big size
with low sounds. John Ohala's paper has the telling
title "The frequency code underlies the sound-symbolic
use of voice pitch". Based on Eugene Morton's
ethological work, Ohala explores some voice-pitch-related
human responses, including responses to intonation.1
He claims that the frequency code underlying
certain aspects of the sound-symbolic use of voice
pitch is not merely an intercultural, but also a cross-species
phenomenon. The reason is that this frequency code
has great survival and evolutionary value both in
mating and settling disputes:
Animals in competition for some resource attempt to
intimidate their opponent by, among other things, trying
to appear as large as possible (because the larger
individuals would have an advantage if, as a last resort,
the matter had to be settled by actual combat). Size
(or apparent size) is primarily conveyed by visual
means, e.g. erecting the hair or feathers and other
appendages (ears, tail feathers, wings), so that the
signaler subtends a larger angle in the receiver's
visual field. There are many familiar examples of this:
threatening dogs erect the hair on their backs and
raise their ears and tails, cats arch their backs,
birds extend their wings and fan out their tail feathers.
[...] As Morton (1977) points out, however, the F0
of voice can also indirectly convey an impression of
the size of the signaler, since F0, other things being
equal, is inversely related to the mass of the vibrating
membrane (vocal cords in mammals, syrinx in birds),
which, in turn, is correlated with overall body mass.
Also, the more massive the vibrating membrane, the
more likely it is that secondary vibrations could arise,
thus giving rise to an irregular or "rough"
voice quality. To give the impression of being large
and dangerous, then, an antagonist should produce a
vocalization as rough and as low in F0 as possible.
On the other hand, to seem small and non-threatening
a vocalization which is tone-like and high in F0 is
called for. [...]. Morton's (1977) analysis, then,
has the advantage that it provides the same motivational
basis for the form of these vocalizations as had previously
been given to elements of visual displays, i.e. that
they convey an impression of the size of the signaler.
I will henceforth call this cross-species F0-function
correlation "the frequency code" (Ohala, 1994: 330).
Voice frequency gives, then, information not about the mass of the body, but about the mass of the vibrating membrane which, in turn, may or may not be correlated with the mass of the body. A bass singer may be slim, it is his vocal chords that must be of a substantial size.
In another paper in the same book, Eugene Morton explores
avian and mammalian sounds used in hostile or "friendly,"
appeasing contexts. He provides two tables in which
sounds given by aggressive and appeasing birds and
mammals are listed. "Aggressive animals utter
low-pitched often harsh sounds, whose most general
function is to increase the distance between sender
and receiver. Appeasing animals use high-pitched, often
tonal sounds, whose most general function is to decrease
the distance or maintain close contact by reducing
the fear or aggression in the receiver" (Morton,
1994: 350-353). Subsequently (353-356) he expounds a
conception of sound--size symbolism in animals similar
to the one quoted above from Ohala.
This conception may have far-reaching implications, beyond what is conspicuously suggested by Ohala and Morton. At the end of an important theoretical statement of research done at the Haskins Laboratories, Liberman (1970: 321) says: "One can reasonably expect to discover whether, in developing linguistic behavior, Nature has invented new physiological devices, or simply turned old ones to new ends". I will suggest that in some cases at least old cognitive and physiological devices are turned to linguistic, even aesthetic, ends. This seems to reflect Natures parsimony.
What is the relationship between being dangerous and
having an irregular or "rough" voice quality;
or between seeming non-threatening and a
vocalization which is tone-like? To answer this question,
one must realise that "noises" are irregular
sounds, "tones" are regular, periodic sounds.
Ohala and Morton mention this issue merely as a corollary
of "deep" and "high" voices. But
this aspect of nonhuman vocalisation may throw an interesting
light on certain widespread intuitions in the poetic
mode of speech perception, namely, that periodic consonants
(e.g., [m], [n]) are perceived as soft, mellow, and appeasing, whereas
aperiodic continuants (e.g., [s], [z]) as harsh, strident,
turbulent, and the like. In fact, what I wrote about
the poetic effects of periodic and aperiodic speech
sounds may apply, mutatis mutandis, to this echological
problem as well:
Periodic sounds have been described (May and Repp, 1982:
145) as "the recurrence of signal portions with
similar structure", whereas aperiodic stimuli
as having "randomly changing waveform", that
"may have more idiosyncratic features to be remembered".
The recurring signal portions with similar structures
may arouse in the perceiver a relatively relaxed kind
of attentiveness (there will be no surprises, one may
expect the same waveform to recur). Thus, periodic
sounds are experienced as smoothly flowing. The randomly
changing waveforms of aperiodic sounds, with their
"idiosyncratic features", are experienced
as disorder, as a disruption of the "relaxed kind
of attentiveness" (Tsur, 1992: 44).
In some circumstances unpredictability is a dangerous
thing. Sound gives information about physical changes
in one's environment. Randomly changing sounds give
information about unpredictable changes. So they force
one to be constantly on the alert. The survival purpose
of such alertness is conspicuous. Even in animal communication, however, an irregular or "rough" voice quality is sometimes "symbolic"; it constitutes no danger in itself, but has a common ingredient with dangerous circumstances: unpredictability. In the poetic mode
of speech perception, response to regular or randomly
changing waveforms is turned to an aesthetic end: it
assumes "purposiveness without purpose".
The foregoing conception may illuminate the motor theory
of speech perception too, from an unexpected angle. This
theory assumes that in the production as well as in
the perception of speech we attend from the acoustic
signal to the combination of muscular movements that
produce it (even in the case of hand-painted spectrograms);
and from these elementary movements to their joint
purpose, the phoneme. The best approximation to the
invariance of phonemes seems to be, according to Liberman
et al. (1967: 43, and passim), by going back in the
chain of articulatory events, beyond the shapes that
underlie the locus of production, to the commands that
produce the shapes. "There is typically a lack
of correspondence between acoustic cue and perceived
phoneme, and in all these cases it appears that perception
mirrors articulation more closely than sound. [...]
This supports the assumption that the listener uses
the inconstant sound as a basis for finding his way
back to the articulatory gesture that produced it and
thence, as it were, to the speaker's intent" (Liberman
et al., 1967: 453). If Ohala and Morton are right,
this mechanism underlying speech perception is a less
recent invention of evolution than might be thought.
The lion's roar, for instance, follows a similar course.
The F0 of voice can convey an impression of the size
of the mass of the vibrating membrane and, indirectly,
of the size of the signaler; in other words, the listener
uses the inconstant sound as a basis for finding his
way back to the articulatory organs and gestures that
produced it and thence, as it were, to the roarer's
intent.
Sound Symbolism and Referent's Size
The foregoing discussion has established a causal relationship as well as structural resemblance between the frequency and perceived size of sounds on the one hand, and the physical size of their vibrating source on the other. The association of small size with high frequency and of large size with low frequency becomes a "meaning potential" of sounds, which may be actualized in sound--referent relations too. In the chapter "Some Spatial and Tactile Metaphors
for Sounds" of my 1992 book I also discussed vowel
symbolism for size and distance. Among others, I quoted
Ultan (1978) who, by examining a total of 136 languages,
tested the hypothesis that diminutive sound symbolism
is associated with marked phonological features (high
and/or front vowels and palatal or fronted consonants).
He found that diminutive is most often symbolized by
high or high front vowels, high tone, or various kinds
of consonantal ablaut. Proximal distance is symbolized
overwhelmingly by front or high vowels. To take a language
not included in Ultan's sample, my native Hungarian,
itt means "here", ott means "there",
ez means "this", az means "that".
Így means "in this fashion", úgy
means "in that fashion"; ilyen means "of
this kind", olyan "of that kind", and
so forth. "Since high front vowels reflect proportionately
higher second formant frequencies, and the higher the
tone the higher the natural frequency, there appears
a correspondence between a feature of high frequency
(= short wavelength in physical terms) and the category
of small size" (Ultan, 1978: 545). Likewise, for
the same reasons, the received view is that in Western
languages /i/ is small and /a/ is big.2
In a mind-expanding paper on the word class of "expressives"3 in Bahnar, a Mon-Khmer language
of Vietnam, Gérard Diffloth claims that in this
word class /i/ signifies "big", and /a/ "small".
This throws my foregoing argument into an exciting
perspective. At first sight the paper provides outright
refutation of one of my pet beliefs; but in the final
resort it lends massive support to my wider conceptions,
that speech events (speech sounds and articulatory
gestures) do have certain (sometimes conflicting) combinational
potentials, which may be activated, after the event,
by certain meaning components. Diffloth points out
the following relationships between referent size and
vowel height in Bahnar:4
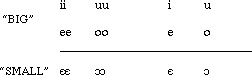
Examples ("D. red." = "Descriptive reduplication"):

and so forth. There are examples in which a three-way
gradation is given, with high vowels providing a third
degree: "enormous":
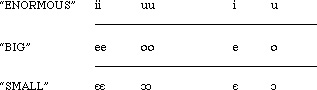
In both the two-way and three-way division "the
iconic values of the vowels are, roughly speaking:
High = Big and Low = Small, exactly opposite to the
English /i/ = Small and /a/ = Big, claimed to be universal.
There is nothing peculiar about this Bahnar system,
and one can easily find an iconic basis for it. In
the articulation of high vowels, the tongue occupies
a much larger volume in the mouth than it does for
low vowels. The proprioceptive sensation due to this,
reinforced by the amount of contact between the sides
of the tongue and the upper molars, is available to
all speakers and is probably necessary to achieve a
precise articulatory gesture. [...] In this perspective,
two different languages may easily use the same phonetic
variable (vowel height) to convey the same range of
sensations (size), and come up with exactly opposite
solutions, both being equally iconic; all they need
to do is focus upon different parts of the rich sensation
package provided by articulatory gestures, in our case
the volume of the tongue instead of the size of the
air passage between it and the palate". Now consider
such pairs of English synonyms as big and large, or
small and little one member of which contains a high
vowel, the other a low one. One may account for their
coexistence in one language in one of two ways: either
by assuming that the relationship between sound and
meaning is arbitrary, or by assuming that speakers
and listeners intuitively focus upon different parts
of "the rich sensation package" provided
by either the articulatory gestures or the speech signal
in pronouncing these words. Shifting attention from
one part of "the rich sensation package"
to another is what Wittgenstein called "aspect-switching",
prompted by the meanings of the words.
There are two conspicuous common features in Diffloth's
corpus and my foregoing examples from Hungarian. First,
the sound--meaning relationship, if present, does
not take the shape of a statistical tendency in a huge
aggregate of isolated words; it is displayed by minimal
pairs of straightforward antonyms. Second, phonetically,
these pairs are opposed in only one pair of vowels;
semantically, too, they are contrasted in one feature.
All the rest is really equal. In other words, size--sound symbolism is formally lexicalised. This lexical
feature reflects creative phonetic intuitions in the
distant past which have fossilised by now; the present-day
language-user may attend away from the sound symbolism
of "high" and "low". So, these
pairs of words are structurally different from such
clusters of synonyms and antonyms as big and large,
or small and little. The two systems, however, are
opposed in one interesting feature. In Hungarian there
is vowel harmony. Consider the pair ilyen  and
olyan
and
olyan  The size-symbolic contrast is
carried by the /i~o/ opposition; but this affects the
relative height of the second vowel too. In Diffloth's
examples from Bahnar, by contrast, the other vowels
may vary independently.
The size-symbolic contrast is
carried by the /i~o/ opposition; but this affects the
relative height of the second vowel too. In Diffloth's
examples from Bahnar, by contrast, the other vowels
may vary independently.
I have a vested theoretical interest that Diffloth's
explanation should be valid. It would reinforce my
conception according to which sound symbolism is part
of a complex event, comprising meanings, articulatory
gestures, sound waves, etc. Each one of these components
has an indefinite number of features, which give rise
to a multiplicity of sometimes conflicting combinational
potentials. Strong intuitions concerning sound symbolism
are generated by selecting a subset of available features
on the semantic, acoustic, and articulatory levels.
When conflicting intuitions are reported, attention
is shifted from one subset to another.
When, however, I tried to pronounce the speech sounds
which Diffloth designates "high", I noticed
that his description suits [i] extremely well;
but not [u].5 In view of the examples he provides, whatever
explanation suits [i] should suit [u] too.
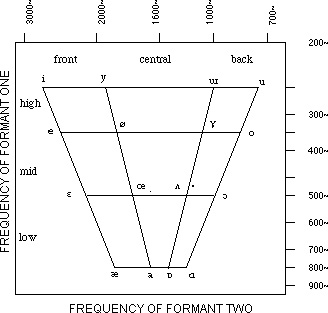
Figure 1 The acoustic and articulatory location of the
synthetic vowels,
plotted according to the frequency
positions of the first and second formants.
When we compare Ultan's and Diffloth's explanations,
we get a clue for solving the problem. Speaking of
"high" and "low", Ultan means relative
formant frequency; Diffloth means articulatory location.6 Consider Figure 1. The words "front,
central, back, high, mid, low" refer to articulatory location.
The numbers refer to formant frequency.
The "height" of the articulatory location
of a vowel is in an inverse relation to the frequency
of its first formant. The higher the articulatory location,
the lower is the formant frequency. In fact, we should
re-write Diffloth's above statement as "In the
articulation of front vowels, the tongue occupies a
much larger volume in the mouth than it does for back
vowels". This would, of course, suit the high
and low vowels arranged by the frequency of the second
formant, according to which /i/ is "high",
/u/ is "low". But the scales of Diffloth's
examples from Bahnar reflect relative frequencies of
the first formant, according to which /i/ and /u/ are
of equal height, /e/ and /o/ are of equal height, and so forth.
So, we must assume that the conflicting sound-symbolisms of Bahnar and of Hungarian (or English) are generated not by attending to different aspects of the articulatory
gesture, but by attending to different formants of
the speech signal. When attending to the frequencies
of the first formant, the principle of low is "big"
and high is "small" is meticulously preserved
in Bahnar too.
Thus, the words high and low are ambiguous in this context.
If we rely on the relative height of articulation in
Bahnar, high will be "big", low will be "small".
If we rely on relative first-formant frequencies, high
will be "small" and low will be "big"
in Bahnar too. How can we know, then, which one is
the "correct" identification? I have to admit
that this is not clear at all. My foregoing discussion
apparently provides support for both possibilities.
In proposing the "Poetic Mode of speech perception",
I relied on "rich precategorial auditory information".
This would favour the "frequency code" conception.
With reference to the motor theory of speech perception,
however, I quoted Liberman saying "in all these
cases it appears that perception mirrors articulation
more closely than sound". This would favour the
articulatory gesture conception.7 I propose the following
way-out from this muddle. By this statement, Liberman
referred to the perception of phonetic categories.
Perceptual and emotional symbolism, by contrast, is
founded precisely on the rich precategorial auditory
information which escapes categorial perception.To be sure, articulatory gestures do have a crucial kinaesthetic effect on how speech sounds feel (see above footnote 5); but we are dealing here with an auditory phenomenon: the perceived size of speech sounds. We actually perceive high-frequency sounds as thinner than low-frequency sounds even when they are played on the violin or the piano, where no articulatory gestures are involved. 8
The notion of "consistency" too may be relevant
here. Ultan accounts for his intercultural findings
with reference to second-formant frequency. Ohala speaks
of the "frequency code" in terms of cross-species
F0-function correlation. When we apply this frequency
code to first-formant frequencies in Diffloth's findings
in Bahnar, they become consistent with earlier findings
in other languages. "The records show that there
are well-developed sound-symbolic systems where vowel
quality is used with systematic results exactly opposite
to those predicted" (Diffloth 1994: 107) -- provided
that we change the rules of the game.
I know, of course,
nothing about the phonetic intuitions of Bahnar-speakers;
nor did Diffloth make any claims about them.
When I first read Diffloth's paper, I thought that his
examples were counterexamples to the widespread belief
(which I too entertained), that high sounds (including
high vowels) tended to suggest small referents, whereas
low sounds and vowels large referents. By the same
token, I thought, it supported my higher generalisations
concerning human flexibility in switching between various
aspects of the same speech sounds. His explanation,
however, based on articulatory gestures, conflicted
with the linguistic facts he adduced. The present paper
proposed an analysis that elucidated the problem and
lended support to both of my former beliefs. I am most
sympathetic with Diffloth in "deploring the incorrect
use of the term 'universal' to mean simply 'found in
a number of languages'". But, as far as the present
issue is concerned, the convincing counterexamples
are still to be adduced.
Notes
1. Ohala's findings illuminate some poorly-understood aspects
of the artistic recitation of metered texts too. I
am currently working on a paper in which I explore
this issue. [back]
2. I wonder whether
this system of front (high) vowels suggesting great
distance and back (low) vowels suggesting small distance
can be related to Morton's claim that aggressive
animals utter low-pitched sounds, whose most general
function is to increase the distance between sender
and receiver, whereas appeasing animals use high-pitched
sounds, whose most general function is to decrease
the distance or maintain close contact by reducing
the fear or aggression in the receiver. [back]
3. "I have used the term 'expressives' to refer to this basic
part of speech, which is alien to Western tradition
but can be defined in the additional way by its distinct
morphology, syntactic properties, and semantic characteristics"
(Diffloth, 1994: 108). [back]
4. Let me say at once that I know
nothing about Bahnar or any other Vietnamese language
except what I read in Diffloth's paper. Everything
I say on this language is based on what I read in that
paper. [back]
5. This does not imply that the much larger volume
which the tongue occupies in the mouth and the larger
surface of contact with the palate may not affect the
perceived quality of speech sounds, e.g., their perceived
wetness. Consider: "Les consonnes palatales ou
palatalisées étaient senties comme particulièrement
mouillées. Par rapport á un l palatisée,
[...] le l simple passe pour sec" (Fónagy,
1979: 19). Fónagy explains this judgment as
follows: "Selon les palatographies et radiographies,
les occlusives amouillées, palatales ou palatalisées,
se distinguent des autres par un contact nettement
plus large du dos de la langue et du palais. Ceci revient
a dire que la sensation kinesthésique du contact
de surfaces des deux muqueuses, donc mouillées
est particulièrement nette" (Fónagy,
1979: 98). [back]
6. Characterisitcally, Diffloth accounts for Ultan's findings, as for his
own findings, in terms of articulatory gestures, not
frequencies: "in our case the volume of the tongue
instead of the size of the air passage between it and
the palate". [back]
7. By the way, the phrase "rich precategorial auditory information", too, is derived from Liberman. [back]
8. Against my own position one may adduce the following observation: if asked "Can you experience /u/ as low, /i/ as high?", most people will answer in the affirmative; again, if asked "Can you experience /i/ and /u/ as equally high?", many people will answer in the affirmative; but if asked "Can you experience /i/ and /u/ as equally low?", most people, at least in the Western tradition, will answer that they don't know what you are talking about. [back]
References
Brown, Roger (1968) Words and Things. New York: The
Free Press.
Delattre, Pierre, Alvin M. Liberman, F. S. Cooper &
L. J. Gerstman (1952) "An Experimental Study of
the Acoustic Determinants of Vowel Color". Word
8: 195-210.
Diffloth, Gérard (1994) "i: big, a: small",
in Hinton, Leanne, Johanna Nichols, and John J. Ohala
eds. Sound Symbolism. Cambridge: Cambridge University
Press. 107114.
Fónagy, Iván (1979) La Métaphore
en Phonétique. Ottava: Didier.
Hrushovski, Benjamin (1968) "Do Sounds Have Meaning?
The Problem of Expressiveness of Sound-Patterns in
Poetry". Hasifrut 1: 410-420 (in Hebrew). English
Summary: 444.
Hrushovski, Benjamin (1980) "The Meaning of Sound
Patterns in Poetry: An Interaction View". Poetics
Today 2: 39-56.
Ladefoged, Peter (1975) A Course in Phonetics. New York:
Harcourt, Brace, and Jovanovich.
Liberman, A. M. (1970) "The Grammars of Speech and Language". Cognitive Psychology 1: 301-323.
Liberman, A. M., F. S. Cooper, D.P. Shankweiler, and
M. Studdert-Kennedy (1967) "Perception of the
Speech Code", Psychological Review 74: 431-461.
May, Janet and Bruno H. Repp (1982) "Periodicity and Auditory Memory". Status Report on Speech Research SR-69: 145-149, Haskins Laboratories.
Morton, Eugene S. (1994) "Sound Symbolism and its
Role in Non-Human Vertebrate Communication" in
Hinton, Leanne, Johanna Nichols, and John J. Ohala
eds. Sound Symbolism. Cambridge: Cambridge University
Press. 348365.
Ohala, John J. (1994) "The Frequency Code Underlies
The Sound-Symbolic Use of Voice Pitch", in Hinton,
Leanne, Johanna Nichols, and John J. Ohala eds. Sound
Symbolism. Cambridge: Cambridge University Press. 325347.
Polányi, Michael (1967) The Tacit Dimension.
Garden City, N.Y.: Anchor Books.
Tsur, Reuven (1992)What Makes Sound Patterns Expressive:
The Poetic Mode of Speech-Perception. Durham N. C.:
Duke UP.
Tsur, Reuven (2001) "Onomatopoeia: Cuckoo-Language
and Tick-Tocking -- The Constraints of Semiotic Systems".
Iconicity In Language. Available Online:
http://www.trismegistos.com/IconicityInLanguage/Articles/Tsur/default.html
Wittgenstein, Ludwig (1976) Philosopical Investigations.
Oxford: Blackwell.

Back to home page
Back to "Occasional Papers"
Back to Contents page
Original file name: Size-Sound Symbolism - converted on Thursday, 15 January 2004, 13:46
This page was created using TextToHTML. TextToHTML is a free software for Macintosh and is (c) 1995,1996 by Kris Coppieters