

The early announcements about the capabilities of NXT's included the following statements about the sound sensor (Mindstorms Education NXT blog entry, February 24th 2006):
The sound sensor also recognizes sound pattern recognition. One clap, for instance, could be programmed to command a certain behavior, but two claps could be programmed to do a behavior that is much different.
In addition to sound pattern recognition, the sensor also features tone recognition. A high pitch would command a different action than a low pitch.
When I was a kid, my brother and I had a Lego train accessory (set 139) that controled a Lego train with a special Lego whisle and a small electronic controller. (Unfortunately, we lost the whisle fairly quickly.) The electronic controller recognizes the frequency of the whisle's sound and started or stoped the train. So I was excited about being able to recognize tones with the NXT.
The sound sensor that actually comes with the NXT, however, only measures amplitude (the strength of sound). The difference between one clap and two is in the pattern of amplitude change, so it the NXT should be able to recognize these sound patterns. I don't see how the NXT can recognize specific tones. I tried to sample the sound sensor as fast as possible, but with NXT-G, the fastest rate was only about 20-30 samples per second. This is not fast enough to recognize tones in the range of human hearing.
So as far as I can tell, the NXT cannot recognize tones with its sound sensor. (If you found a way to do it, let me know!) But recognizing clap patterns should be doable, so I tried.
I started by investigating how the sound sensor hears claps. That is, I wanted to understand what a sequence of sound-sensor readings would look like during a clap. To do that, I wrote a little NXT-G program that made 1000 sound-sensor readings. After each reading, it read the value of a timer and sent the two numbers (the timing data and the sensor reading) to my PC using Bluetooth. On the PC, my program NXTender recorded these pairs of numbers in a file.
I loaded the numbers into a program that can plot data on a graph (Matlab, but any spreadsheet or data-analysis program can be used as well) and plotted them. The following graphs show the results. The graph on the left shows the entire recording, and the graph on the right zooms in on a short subsequence that includes three claps in a row. Actual sound-sample measurments are represented by black dots; the red lines only connect the dots.
|
|
The sound sensor readings do not represent the actual sound
well. A recording of similar claps by a PC (using Windows' audio
recording tool to record a wav file with a
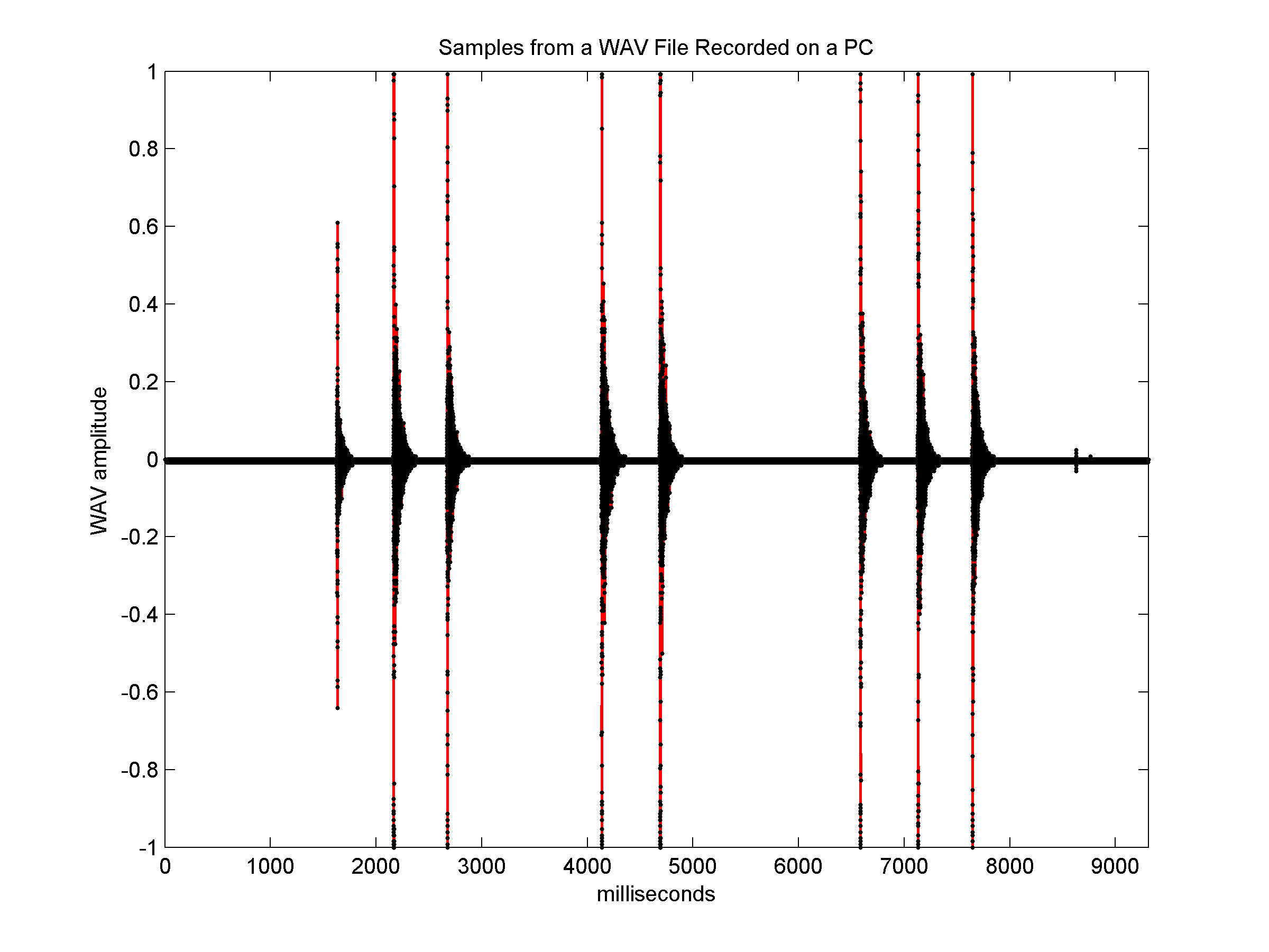
sample rate of 22.5 kHz) shows quite a different behavior. The graph on
the left shows the samples in the PC's recording for a sequence of
about 9 seconds, and the graph on the right again zooms on a short
subsequence.
 |
 |
The PC recording, which represents the sound more accurately
than the NXT's sound-sensor readings, shows that the claps are much
more localized in time (here
is the wav file, about 200 KB).
They start with a very sudden rise in amplitude, which quickly goes
back down to a low level (but higher than the level at quiet periods),
which dies out completely in about 100 ms or so. The graph of the NXT's
sound sensor also starts with a rapid rise at the beginning of each
clap, usually within 1 or 2 samples (less than 20 ms). But the
amplitude returns to low much more slowly. It takes about 200 ms for
the sensor readings to go back down to 50, and almost 500 ms to go back
to the quiet level.
But since we need to recognize claps using readinds of the NXT's sound sensor, the actual acoustic properties of clapping hands are not important. What is important is what pattern of readings these sounds produce on the NXT's sound sensor, because these patterns are what we are trying to recognize.
Given this rough knowledge of the pattern of sensor readings caused by clapping, we can specify the pattern that we want the program to recognize. Our knowledge is rough because we only have one sample of one person clapping. It would be better to work with multiple sample of multiple people clapping. It would also be good to have NXT sound-sensor recordings of sounds that are not clapping, like people talking, shouting, things falling, and so on. These recordings would help us ensure that our specification includes as many forms of hand clapping as possible while excluding as many non-clapping sounds as possible.
But we can still draw a useful specification from this single sample. Also, we want to recognize the pattern with a reasonably simple NXT-G program, so it helps to keep the specification simple.
It's a good idea to keep the specification separate from the implementation (the actual program). If the program does not recognize claps correctly, the fault could be either a result of a wrong specification, or of a wrong implementation. Separating the specification and the implementation will help us debug the recognizer.
Here is the specification that I used in the recognizer. The specification relies on timing, not on counting samples, because a program with multiple threads is likely to sample at a slower rate than a test program that does nothing but recognize claps.
In this specification, we really only care about 3 samples: the first should be low, the second should be very high and follow the first within 25 milliseconds, and the third should again be low and should follow the second within 250 milliseconds. The fast rise ensures that we will not classify slowly-rising sounds as claps. The requirement that the amplitude falls back down within 250 ms ensures that we will not classify as claps sounds like that of a food processor that starts to work nearby. Such a sound would result in a rapid rise in amplitude, but without a quick fall back to quiet.
Apart from the specification of a single clap, we also need to specify how the program would count claps:
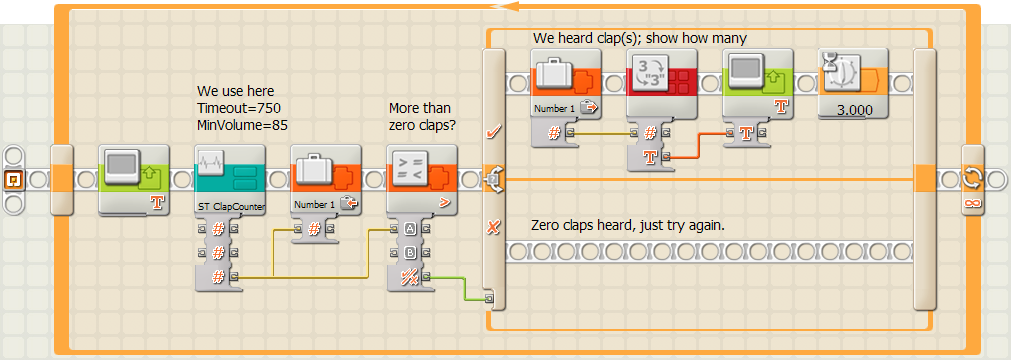
Here is a MyBlock that implements this specification. It has two inputs, the time to wait for a clap after the end of the previous one, and the sound level that is required for a clap. It returns the number of claps that it heard. If nobody is clapping, it is very likely to return a value of zero. It does so after waiting the given amount of waiting time.

As you can see, it is a relatively complex my block. On my computer (a 1.7 MHz Pentium M with 1 GB of memory) the drag-and-drop of blocks became slow when the code grew. Also, the automatic routing of the sequence beam sometimes produced strange results (you can see them in the figure; I could not get rid of them), and the output terminal got hidden behind the large loop and was difficult to make it visible.
Here is a sample program that uses the MyBlock. It calls it repeatedly. If it hears claps, it shows the number for 3 seconds before calling it again. If it hears nothing, it calls it again immediately. Clap only when the screen is blank, not when it is showing a number.
I hope it will, but it might not. If it does not, try to clap harder. Some of my family members do not clap as hard as I do, so the program does not always recorgnize them clapping, or it does not count correctly, because it only hears some of the claps. Also, it helps to clap at a steady rate. I clap at about 2-3 claps per second, so the parameters are tuned to this rate.
Of course, if you relax the parameters of the program enough to recognize slow and weak claps, it will also count many non-clapping sounds, like people talking. So it is better to try to make your clapping distinct from other sounds (e.g., very loud) than to relax the parameters.
I have found that it is often easier to produce consistent and loud clapping-like sounds from toy tambourines and similar musical instruments than from actually clapping your hands. My kids had trouble clapping hard enough for the program, but no problems making the program correctly count up to 10 or 20 with a toy tambourine.
© 2006, Sivan Toledo