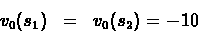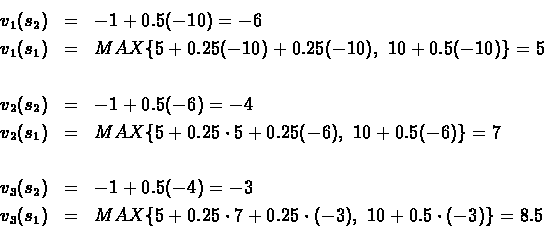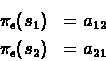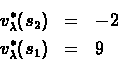Next: Policy Iteration
Up: Finding the Optimal Policy:
Previous: Convergence of Value Iteration
Example: Running Value Iteration Algorithm
(Consider the MDP in figure ![[*]](/usr/local/lib/latex2html-98.1p1/icons.gif/cross_ref_motif.gif) )
)
Let:
Step 1: We Initialize:
Steps 2-5:
Step 6:
Note that the iterated value approaches
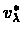 ,
which is:
,
which is:
Yishay Mansour
1999-12-18